
 |
In Section III-B, we derived the optimality criteria for sequential
prefetching in the steady state. We have not discussed the behavior of the
sequential prefetching algorithms when the average length of sequences is rather
short. Apart from providing close to optimal performance for long streams,
AMP achieves the best overall performance for short streams as well.
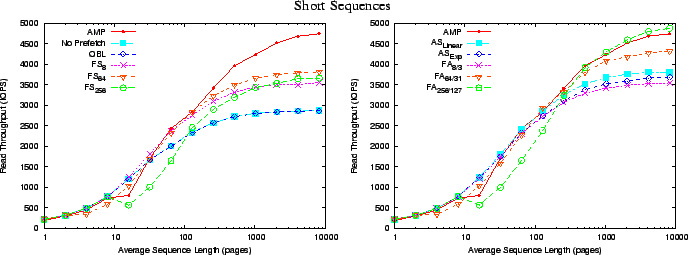
Figure 12 shows the throughput of various algorithms as the
length of sequences go from ![]() (effectively random) to
(effectively random) to ![]() read I/Os. The AS algorithms
along with FS
read I/Os. The AS algorithms
along with FS
![]() and FA
and FA
![]() perform well for short sequence
lengths as they have a smaller
perform well for short sequence
lengths as they have a smaller ![]() and suffer from less prefetch wastage.
As the sequence lengths are increased, the FA
and suffer from less prefetch wastage.
As the sequence lengths are increased, the FA
![]() becomes a strong
contender. The fact that AMP starts off with a small
becomes a strong
contender. The fact that AMP starts off with a small ![]() and adapts
to make it larger if necessary makes it perform reasonably well for short
sequences. As the length of sequences becomes larger, the adaptive power
of AMP allows it discover the right combination of
and adapts
to make it larger if necessary makes it perform reasonably well for short
sequences. As the length of sequences becomes larger, the adaptive power
of AMP allows it discover the right combination of ![]() and
and ![]() .
AMP is therefore not only provably optimal for steady sequential streams
but also has the best overall performance for short sequences as well.
.
AMP is therefore not only provably optimal for steady sequential streams
but also has the best overall performance for short sequences as well.