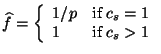We use two definitions for counting flows: active flows and flow arrivals. A
flow is active during a time bin if it sends at least one packet during that
time bin. Consecutive TCP connections between the same two computers that happen
to share the same port numbers are considered a single flow and they will be
reported in the same flow record under our current assumptions. Active flows
with none of their packets sampled by the flow slicing process, will have no
records; at least some of the flow records we get should be counted as more than
one active flow, so that the total estimate will be unbiased. We count records
with a packet counter ![]() of
of ![]() as
as ![]() flows and other records as
flows and other records as ![]() flow
and this gives us unbiased estimates for the number of active flows.
flow
and this gives us unbiased estimates for the number of active flows.
Proof: There are three possible cases: if a packet before the
last gets sampled, ![]() , if only the last packet gets sampled
, if only the last packet gets sampled ![]() ,
and if none of the packets gets sampled there will be no flow record,
so the contribution of the flow to the estimate of the number of
active flows will be
,
and if none of the packets gets sampled there will be no flow record,
so the contribution of the flow to the estimate of the number of
active flows will be
![]() . The probability of the first
case is
. The probability of the first
case is
![]() , the probability of the second is
, the probability of the second is
![]() and that of the third is
and that of the third is
![]() .
.
The estimators for the number of bytes and packets in a flow were trivial to
generalize to the case where we apply random packet sampling before flow slicing
because the expected number of packets and bytes after packet sampling was
exactly ![]() times the number before. For the number of active flows there is no
such simple relationship and actually it has been shown that it is impossible to
estimate without significant bias the number of active flows once random
sampling has been applied [5]. But by changing
slightly the definition of flow counts we can take advantage of the SYN flags
used by TCP flows.
times the number before. For the number of active flows there is no
such simple relationship and actually it has been shown that it is impossible to
estimate without significant bias the number of active flows once random
sampling has been applied [5]. But by changing
slightly the definition of flow counts we can take advantage of the SYN flags
used by TCP flows.