| ||||||||||||||||||||||||||||||||||||||||||||||||||||
|
FAST '04 Paper
[FAST '04 Technical Program]
MEMS-based storage devices and standard disk interfaces:
|
| Capacity | 3.46 GB |
|---|---|
| Average access time | 0.88 ms |
| Streaming bandwidth | 76 MB/s |
Table 1: G2 MEMStore parameters. These parameters are for the G2 MEMStore design from [28].
The MEMStore that we use for evaluation is the G2 model from [28]. Its basic parameters are given in Table 1. We use DiskSim, a freely-available storage system simulator, to simulate the MEMStore [6].
| Capacity | 41.6 GB |
|---|---|
| Rotation speed | 55,000 RPM |
| One-cylinder seek time | 0.1 ms |
| Full-stroke seek time | 2.0 ms |
| Head switch time | 0.01 ms |
| Number of cylinders | 39,511 |
| Number of surfaces | 2 |
| Average access time | 0.88 ms |
| Streaming bandwidth | 100 MB/s |
Table 2: Uberdisk parameters. The Uberdisk is a hypothetical future disk drive. Its parameters are scaled from current disks, and are meant to represent those of a disk that matches the performance of a MEMStore. The average response time is for a random workload which exercised only the first 3.46 GB of the disk in order to match the capacity of the G2 MEMStore.
For comparison, we use a hypothetical disk design, which we call the Uberdisk, that approximates the performance of a G2 MEMStore. Its parameters are based on extrapolating from today's disk characteristics, and are given in Table 2. The Uberdisk is also modeled using DiskSim. In order to do a capacity-to-capacity comparison, we use only the first 3.46 GB of the Uberdisk to match the capacity of the G2 MEMStore. The two devices have equivalent performance under a random workload of 4 KB requests that are uniformly distributed across the capacity (3.46 GB) and arrive one at a time. Since our model of MEMStores does not include a cache, we disabled the cache of the Uberdisk.
We based the seek curve on the formula from [24], choosing specific values for the one-cylinder and full-stroke seeks. Head switch and one-cylinder seek times are expected to decrease in the future due to microactuators integrated into disk heads, leading to shorter settle times. With increasing track densities, the number of platters in disk drives is decreasing steadily, so the Uberdisk has only two surfaces. The zoning geometry is based on simple extrapolation of current linear densities.
An Uberdisk does not necessarily represent a realistic disk; for example, a rotation rate of 55,000 RPM (approximately twice the speed of a dental drill) may never be attainable in a reasonably-priced disk drive. However, this rate was necessary to achieve an average rotational latency that is small enough to match the average access time of the MEMStore. The Uberdisk is meant to represent the parameters that would be required of a disk in order to match the performance of a MEMStore. If the performance of a workload running on a MEMStore is the same as it running on an Uberdisk, then we can say that any performance increase is due only to the intrinsic speed of the device, and not due to the fact that it is a MEMStore or an Uberdisk. If the performance of the workload differs on the two devices, then it must be especially well-matched to the characteristics of one device or the other.
One of the roles that has been suggested for MEMStores in systems is that of augmenting or replacing some or all of the disks in a disk array to increase performance [28, 32]. However, the lower capacity and potentially higher cost of MEMStores suggest that it would be impractical to simply replace all of the disks. Therefore, they represent a new tier in the traditional storage hierarchy, and it will be important to choose which data in the array to place on the MEMStores and which to store on the disks. Uysal et al. evaluate several methods for partitioning data between the disks and the MEMStores in a disk array [32]. We describe a similar experiment below, in which a subset of the data stored on the back-end disks in a disk array is moved to a MEMStore.
 |
 |
|---|---|
| (a) MEMStore | (b) Uberdisk |
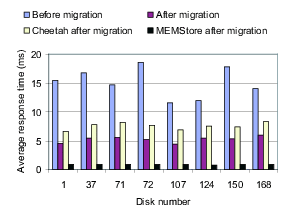
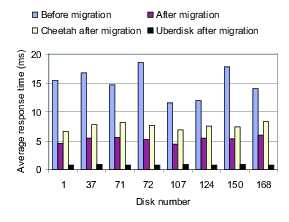
Figure 3: Using MEMStores in a disk array. These graphs show the result of augmenting overloaded disks in a disk array with faster storage components: a MEMStore (a) or an Uberdisk (b). In both cases, the busiest logical volume on the original disk (a 73 GB Seagate Cheetah) is moved to the faster device. Requests to the busiest logical volume are serviced by the faster device, and the traffic to the Cheetah is reduced. The results for both experiments are nearly identical, leading to the conclusion that the MEMStore and the Uberdisk are interchangeable in this role (e.g., it is not MEMStore-specific.)
We can expect some increase in performance from doing this, as Uysal et al. report. However, our question here is whether the benefits are from a MEMStore-specific attribute, or just from the fact that MEMStores are faster than the disks used in the disk array. To answer this question, we apply the specificity test by comparing the performance of a disk array back-end workload on three storage configurations. The first configuration uses just the disks that were originally in the disk array. The second configuration augments the overloaded disks with a MEMStore. The third does the same with an Uberdisk.
The workload is a disk trace gathered from the disks in the back-end of an EMC Symmetrix disk array during the summer of 2001. The disk array contained 282 Seagate Cheetah 73 GB disk drives, model number ST173404. From those, we have chosen the eight busiest (disks 1, 37, 71, 72, 107, 124, 150, and 168), which have an average request arrival rate of over 69 requests per second for the duration of the trace, which was 12.5 minutes. Each disk is divided into 7~logical volumes, each of which is approximately 10 GB in size. For each ``augmented'' disk, we move the busiest logical volume to a faster device, either a MEMStore or an Uberdisk. The benefit should be twofold: first, response times for the busiest logical volume will be improved, and second, traffic to the original disk will be reduced. Requests to the busiest logical volume are serviced by the faster device (either a MEMStore or an Uberdisk), and all other requests are serviced by the original Cheetah disk.
Figure 3(a) shows the result of the experiment with the MEMStore. For each disk, the first bar shows the average response time of the trace running just on the Cheetah, which is 15.1 ms across all of the disks. The second bar shows the average response time of the same requests after the busiest logical volume has been moved to the MEMStore. Across all disks, the average is now 5.24 ms. The third and fourth bars show, respectively, the average response time of the Cheetah with the reduced traffic after augmentation, and the average response time of the busiest logical volume, which is now stored on the MEMStore. We indeed see the benefits anticipated --- the average response time of requests to the busiest logical volume have been reduced to 0.86 ms, and the reduction of load on the Cheetah disk has resulted in a lower average response time of 7.56 ms.
Figure 3(b) shows the same experiment, but with the busy logical volume moved to an Uberdisk rather than a MEMStore. The results are almost exactly the same, with the response time of the busiest logical volume migrated to the Uberdisk being around 0.84 ms, and the overall response time reduced from 15.1 ms to 5.21 ms.
The fact that the MEMStore and the Uberdisk provide the same benefit in this role means that it fails the specificity test. In this role, a MEMStore really can be considered to be just a fast disk. The workload is not specifically matched to the use of a MEMStore or an Uberdisk, but can clearly be improved with the use of any faster device, regardless of its technology.
Although it is imperceptible in Figure 3, the Uberdisk gives slightly better performance than the MEMStore because it benefits more from workload locality due to the profile of its seek curve. The settling time in the MEMStore model makes any seek expensive, with a gradual increase up to the full-stroke seek. The settling time of the Uberdisk is somewhat less, leading to less expensive initial seek and a steeper slope in the seek curve up to the full-stroke seek. The random workload we used to compare devices has no locality, but the disk array trace does.
To explore this further, we re-ran the experiment with two other disk models, which we call Simpledisk-constant and Simpledisk-linear. Simpledisk-constant responds to requests in a fixed amount of time, equal to that of the response time of the G2 MEMStore under the random workload: 0.88 ms. The response time of Simpledisk-linear is a linear function of the distance from the last request in LBN space. The endpoints of the function are equal to the single-cylinder and full-stroke seek times of the Uberdisk, which are 0.1 ms and 2.0 ms, respectively. Simpledisk-constant should not benefit from locality, and Simpledisk-linear should benefit from locality even more than either the MEMStore or the Uberdisk. Augmenting the disk array with these devices gives response times to the busiest logical volume of 0.92 ms and 0.52 ms, respectively. As expected, Simpledisk-constant does not benefit from workload locality and Simpledisk-linear benefits more than a real disk.
Uysal proposed several other MEMStore/disk combinations in [32], including replacing all of the disks with MEMStores, replacing half of the mirrors in a mirrored configuration, and using the MEMStore as a replacement of the NVRAM cache. In all of these cases, and in most of the other roles outlined in Section 2.1, the MEMStore is used simply as a block store, with no tailoring of access to MEMStore-specific attributes. We believe that if the specificity test were applied, and an Uberdisk was used in each of these roles, the same performance improvement would result. Thus, the results of prior research apply more generally to faster mechanical devices.
Mechanical and structural differences between MEMStores and disks suggest that request scheduling policies that are tailored to MEMStores may provide better performance than ones that were designed for disks. Upon close examination, however, the physical and mechanical motions that dictate how a scheduler may perform on a given device continue to apply to MEMStores as they apply to disks. This may be surprising at first glance, since the devices are so different, but after examining the fundamental assumptions that make schedulers work for disks, it is clear that those assumptions are also true for MEMStores.
To illustrate, we give results for a MEMStore-specific scheduling algorithm called shortest-distance-first, or SDF. Given a queue of requests, the algorithm compares the Euclidean distance between the media sled's current position and the offset of each request and schedules the request that is closest. The goal is to exploit a clear difference between MEMStores and disks: that MEMStores position over two dimensions rather than only one. When considering the specificity test, it is not surprising that this qualifies as a MEMStore-specific policy. Disk drives do, in fact, position over multiple dimensions, but predicting the positioning time based on any dimension other than the cylinder distance is very difficult outside of disk firmware. SDF scheduling for MEMStores is easier and could be done outside of the device firmware, since it is only based on the logical-to-physical mapping of the device's sectors and any defect management that is used, assuming that the proper geometry information is exposed through the MEMStore's interface.
The experiment uses a random workload of 250,000 requests uniformly distributed across the capacity of the MEMStore. Each request had a size of 8 KB. This workload is the same as that used in [34] to compare request scheduling algorithms. The experiment tests the effectiveness of the various algorithms by increasing the arrival rate of requests until saturation --- the point at which response time increases dramatically because the device can no longer service requests fast enough and the queue grows without bound.
The algorithms compared were first-come-first-served (FCFS), cyclic LOOK (CLOOK), shortest-seek-time-first (SSTF), shortest-positioning-time-first (SPTF), and shortest-distance-first (SDF). The first three are standard disk request schedulers for use in host operating systems. FCFS is the baseline for comparison, and is expected to have the worst performance. CLOOK and SSTF base their scheduling decisions purely on the LBN number of the requests, utilizing the unwritten assumption that LBN numbers roughly correspond to physical positions [34]. SPTF uses a model of the storage device to predict service times for each request, and can be expected to give the best performance. The use of the model by SPTF breaks the abstraction boundaries because it provides the application with complete details of the device parameters and operation. The SDF scheduler requires the capability to map LBN numbers to physical locations, which breaks the abstraction, but does not require detailed modeling, making it practical to implement in a host OS.
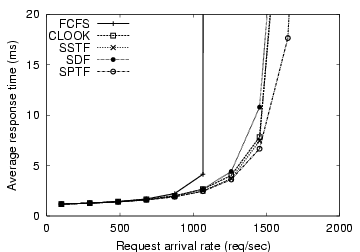
Figure 4: Performance of shortest-distance-first scheduler. A MEMStore-specific scheduler that accounts for two-dimensional position gives no benefit over simple schedulers that use a linear abstraction (CLOOK and SSTF). This is because seek time in a MEMStore is correlated most strongly with only distance in the X dimension.
Figure 4 shows the results. As expected, FCFS and SPTF perform the worst and the best, respectively. CLOOK and SSTF don't perform as well as SPTF because they use only the LBN numbers to make scheduling decisions. The SDF scheduler performs slightly worse than CLOOK and SSTF. The reason is that positioning time is not as well correlated with two-dimensional position, as described in Section 4.2. As such, considering the two-dimensional seek distance does not provide any more utility than just considering the one-dimensional seek distance, as CLOOK and SSTF effectively do. Thus, the suggested policy fails the merit test: the same or greater benefit can be had with existing schedulers that don't need MEMStore-specific knowledge. This is based, of course, on the assumption that settling time is a significant component of positioning time. Section 7 discusses the effect of removing this assumption.
The fundamental reason that scheduling algorithms developed for disks work well for MEMStores are that seek time is strongly dependent on seek distance, but only the seek distance in a single dimension. The seek time is only correlated to a single dimension, which is exposed by the linear abstraction. The same is true for disks when one cannot predict the rotational latencies, in which only the distance that the heads must move across cylinders is relevant. Hence, a linear logical abstraction is as justified for MEMStores as it is for disks.
Of course, there may be yet-unknown policies that exploit features that are specific to MEMStores, and we expect research to continue in this area. When considering potential policies for MEMStores, it is important to keep the two objective tests in mind. In particular, these tests can expose a lack of need for a new policy or, better yet, the fact that the policy is equally applicable to disks and other mechanical devices.
This section describes three MEMStore-specific features that clearly set them apart from disks, offering significant performance improvements for well-matched workloads. Exploiting such features may require a new abstraction or, at least, changes in the unwritten contract between systems and storage.
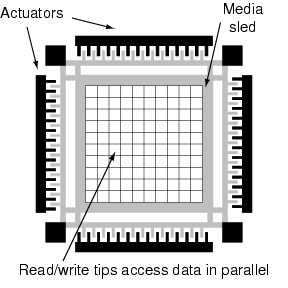
MEMStores have an interesting access parallelism feature that does not exist in modern disk drives. Specifically, subsets of a MEMStore's thousands of read/write tips can be used in parallel, and the particular subset can be dynamically chosen. This section briefly describes how such access parallelism can be exposed to system software, with minimal extensions to the storage interface, and utilized cleanly by applications. Interestingly, our recent work [27] has shown the value of the same interface extensions for disk arrays, suggesting that this is a generally useful storage interface change.
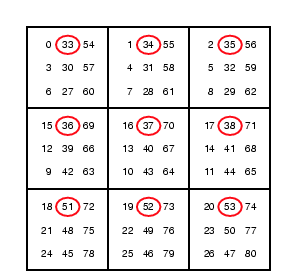
Figure 5: Data layout with a set of equivalent LBNs highlighted. The LBNs marked with ovals are at the same location within each square and, thus, are ``equivalent''. That is, they can potentially be accessed in parallel.
Figure 5 shows a simple MEMStore with nine read/write tips and nine sectors per tip. Each read/write tip addresses its own section of the media, denoted by the nine squares in the figure. Sectors that are at the same physical offset within each square, such as those indicated with ovals, are addressed simultaneously by the tip array. We call these sectors equivalent, because they can be accessed in parallel. But, in many designs, not all of the tips can be actively transferring data at the same time due to power consumption or component sharing constraints. Using a simple API, an application or OS module could identify sets of sectors that are equivalent, and then choose subsets to access together. Since the LBNs which will be accessed together will not fall into a contiguous range, the system will need to be able to request batches of non-contiguous LBNs, rather than ranges.
The standard interface forces applications to map their data into a linear address space. For most applications, this is fine. However, applications that use two-dimensional data structures, such as non-sparse matrices or relational database tables, are forced to serialize their storage in this linear address space, making efficient access possible along only one dimension of the data structure. For example, a database can choose to store its table in column-major order, making column accesses sequential and efficient [3]. Once this choice is made, however, accessing the table in row-major order is very expensive, requiring a full scan of the table to read a single row. One option for making operations in both dimensions efficient is to create two copies of a table; one copy is optimized for column-major access and the other is optimized for row-major access [21]. This scheme, however, doubles the capacity needed for the database and requires that updates propagate to both copies.
With proper allocation of data to a MEMStore LBN space, parallel read/write tips can be used to access a table in either row- or column-major order at full speed [29, 35]. The table is arranged such that the same attributes of successive records are stored in sequential LBNs. Then, the other attributes of those records are stored in LBNs that are equivalent to the original LBNs, as in Figure 5. This layout preserves the two-dimensionality of the original table on the physical media of the MEMStore. Then, when accessing the data, the media sled is positioned and the appropriate read/write tips are activated to read data either in row- or column-major order.
To quantify the advantages of such a MEMStore-specific scan operator, we compare the times required for different table accesses. We contrast their respective performance under two different layouts on a single G2 MEMStore device. The first layout, called normal, is the traditional row-major access optimized page layout used in almost all database systems [20].
The second layout, called MEMStore, uses the MEMStore-specific layout and access described above. The sample database table consists of 4 attributes a1, a2, a3, and a4 sized at 8, 32, 15, and 16 bytes respectively. The normal layout consists of 8 KB pages that hold 115 records. The table size is 10,000,000 records for a total of 694 MB of data.
Figure 6 compares the time of a full table scan for all attributes with four scans of the individual attributes. The total runtime of four single-attribute scans in the MEMStore case takes the same amount of time as the full table scan. In contrast, with the normal layout, the four successive scans take four times as long as the full table scan. Most importantly, a scan of a single attribute in the MEMStore case takes only the amount of time needed for a full-speed scan of the corresponding amount of data, since all of the available read/write tips read records of the one attribute. This result represents a compelling performance improvement over current database systems. This policy for MEMStores passes both the specificity test and the merit test.
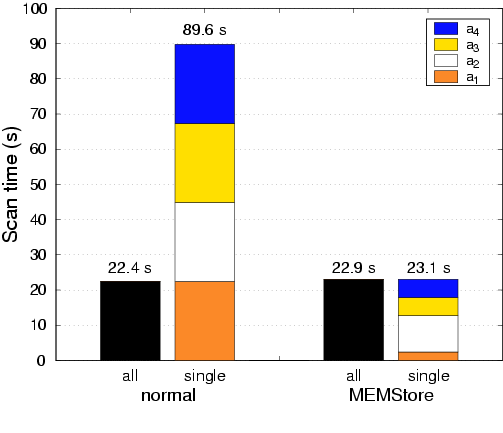
Figure 6: Database table scan with different number of attributes. This graph shows the runtime of scanning 10,000,000 records using a G2 MEMStore. For each of the two layouts, the left bar, labeled ``all,'' shows the time to scan the entire table with four attributes. The right bar, labeled ``single,'' is composed of four separate scans of each successive attribute, simulating the situation where multiple queries access different attributes. Since the MEMStore layout takes advantage of MEMStore's tip-subset parallelism, each attribute scan runtime is proportional to the amount of data occupied by that attribute. The normal layout, on the other hand, must read the entire table to fetch any one attribute.
Another aspect of MEMStores that differs from disk drives is their ability to quickly access an LBN repeatedly. In a disk, repeated reads to an LBN may be serviced from the disk's buffer, but repeated synchronous writes or read/modify/write sequences will incur a full rotation, 4-8 ms on most disks, for each access. A MEMStore, however, can simply change the direction that the media sled is moving, which is predicted to take less than a tenth of a millisecond [11]. Read/modify/write sequences are prevalent in parity-based redundancy schemes, such as RAID-5, in which the old data and parity must each be read and then updated for each single block write. Repeated synchronous writes are common in database log files, where each commit entry must propagate to disk. Such operations are much more expensive in a disk drive.
Although the volumetric density of MEMStores is on-par with that of disk drives, the per-device capacity is much less. For example, imagine two 100 GB ``storage bricks,'' one using disk storage and the other using MEMStores. Given that the volumetric densities are equal, the two bricks would consume about the same amount of physical volume. But, the MEMStore brick would require at least ten devices, while the disk-based brick could consist of just one device. This means that the MEMStore-based brick would have more independent actuators for accessing the data, leading to several interesting facts. First, the MEMStore-based brick could handle more concurrency, just as in a disk array. Second, MEMStores in the brick that are idle could be turned off while others in the brick are still servicing requests, reducing energy consumption. Third, the overall time to scan the entire brick could be reduced, since some (or all) of the devices could access data in parallel. This assumes that the bus connecting the brick to the system is not a bottleneck, or that the data being scanned is consumed within the brick itself. The lower device scan time is particularly interesting because disk storage is becoming less accessible as device capacities grow more quickly than access speeds [9].
Simply comparing the time to scan a device in its entirety, a MEMStore could scan its entire capacity in less time than a single disk drive. At 100 MB/s, a 10 GB MEMStore is scanned in only 100 s, while a 72 GB disk drive takes 720 s. As a result, strategies that require entire-device scans, such as scrubbing or virus scanning, become much more feasible.
Unfortunately, MEMStores do not exist yet, so there are no prototypes that we can experiment with, and they are not expected to exist for several more years. As such, we must base all experiments on simulation and modeling. We have based our models on detailed discussions with researchers who are designing and building MEMStores, and on an extensive study of the literature. The work and the conclusions in this paper are based on this modeling effort, and is subject to its assumptions about the devices. This section outlines two of the major assumptions of the designers and how our conclusions would change given different assumptions.
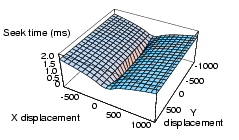
Some of our conclusions are based on the assumption that post-seek settling time will affect one seek dimension more than the other. This effectively uncorrelates seek time with one of the two dimensions, as described in Section 4.2. The assumption is based on the observation that different mechanisms determine the settling time in each of the two axes, X and Y. Settling time is needed to damp oscillations enough for the read/write tips to reliably access data. In all published MEMStore designs, data is laid out linearly along the Y-axis, meaning that oscillations in Y will appear to the channel as minor variations in the data rate. Contrast this with oscillations in the X-axis, which pull the read/write tips off-track. Because one axis is more sensitive to oscillation than the other, its positioning delays will dominate the other's, unless the oscillations can be damped in near-zero time.
If this assumption no longer held, and oscillations affected each axis equally, then MEMStore-specific policies that take into account the resulting two-dimensionality of the seek profile, as illustrated in Figure 7, would become more valuable. Now, for example, two-dimensional distance would be a much better predictor of overall positioning time. Figure 8 shows the result of repeating the experiment from Section 5.4, but with the post-seek settle time set to zero. In this case, the performance of the SDF scheduler very closely tracks shortest-positioning-time-first, SPTF, the scheduler based on full knowledge of positioning time. Further, the difference between SDF and the two algorithms based on single-dimension position (CLOOK and SSTF) is now very large. CLOOK and SSTF have worse performance because they ignore the second dimension that is now correlated strongly with positioning time.
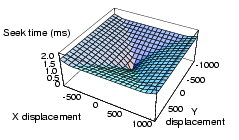
Figure 7: MEMStore seek curve without settling time. Without the settling time, the seek curve of a MEMStore is strongly correlated with displacement in both dimensions [10].
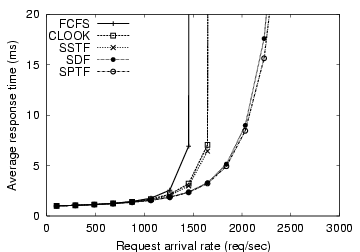
Figure 8: Performance of shortest-distance-first scheduler without settle time. If post-seek settle time is eliminated, then the seek time of a MEMStore becomes strongly correlated with both the X and Y positions. In this case, a scheduler that takes into account both dimensions provides much better performance than those that only consider a single dimension (CLOOK and SSTF).
Another closely-related assumption is that data in a MEMStore is accessed sequentially in a single dimension. One could imagine a MEMStore in which data is accessed one point at a time. As a simple example, imagine that the media sled would move to a single position and then engage 8 × 512 read/write probes (plus ECC tips) in parallel to read one 512 byte sector from the media at once. From that point, the media sled could then re-position in either the X or Y dimension and read another 512 byte sector. In fact, the device could stream sequentially along either dimension. Current designs envision using embedded servo to keep the read/write tips on track, just as in disks [31]. Both servo and code-words would have to be encoded along both dimensions somehow to allow streaming along either. The ability to read sequentially along either dimension at an equal rate could improve the performance of applications using two-dimensional data structures, as described in Section 6.1.1. Rather than using tip subset parallelism, data tables could be stored directly in their original format on the MEMStore, and then accessed in either direction efficiently. Note, however, that the added complexity of the coding and access mechanisms would be substantial, making this unlikely to occur.
One question that should be asked when considering how to use MEMStores in computer systems is whether they have unique characteristics that should be exploited by systems, or if they can be viewed as small, low-power, fast disk drives. This paper examines this question by establishing two objective tests that can be used to identify the existence and importance of relevant MEMStore-specific features. If an application utilizes a MEMStore-specific feature, then there may be reason to use something other than existing disk-based abstractions. After studying the fundamental reasons that the existing abstraction works for disks, we conclude that the same reasons hold true for MEMStores, and that a disk-like view is justified. Several case studies of potential roles that MEMStores may take in systems and policies for their use support this conclusion.
We thank the members of the MEMS Laboratory at CMU for helping us understand the technology of MEMS-based storage devices. We would thank the anonymous reviewers and our shepherd, David Patterson, for helping to improve this paper. We thank the members and companies of the PDL Consortium (EMC, Hewlett-Packard, Hitachi, IBM, Intel, LSI Logic, Microsoft, Network Appliance, Oracle, Panasas, Seagate, Sun, and Veritas) for their interest, insights, feedback, and support. This work is funded in part by NSF grant CCR-0113660.
[1] L. Richard Carley, James A. Bain, Gary K. Fedder, David W. Greve, David F. Guillou, Michael S. C. Lu, Tamal Mukherjee, Suresh Santhanam, Leon Abelmann, and Seungook Min. Single-chip computers with microelectromechanical systems-based magnetic memory. Journal of Applied Physics, 87(9):6680-6685, 1 May 2000.
[2] Center for Highly Integrated Information Processing and Storage Systems, Carnegie Mellon University. https://www.ece.cmu.edu/research/chips/.
[3] G. P. Copeland and S. Khoshafian. A decomposition storage model. ACM SIGMOD International Conference on Management of Data (Austin, TX, 28-31 May 1985), pages 268-279. ACM Press, 1985.
[4] T. E. Denehy, A. C. Arpaci-Dusseau, and R. H. Arpaci-Dusseau. Bridging the information gap in storage protocol stacks. Summer USENIX Technical Conference (Monterey, CA, 10-15 June 2002), pages 177-190, 2002.
[5] Z. Dimitrijevic, R. Rangaswami, and E. Chang. Design and implementation of semi-preemptible IO. Conference on File and Storage Technologies (San Francisco, CA, 21 March-02 April 2003), pages 145-158. USENIX Association, 2003.
[6] The DiskSim Simulation Environment (Version 3.0). https://www.pdl.cmu.edu/DiskSim/index.html.
[7] I. Dramaliev and T. M. Madhyastha. Optimizing probe-based storage. Conference on File and Storage Technologies (San Francisco, CA, 21 March-02 April 2003), pages 103-114. USENIX Association, 2003.
[8] G. R. Ganger. Blurring the line between OSs and storage devices. Technical report CMU-CS-01-166. Carnegie Mellon University, December 2001.
[9] J. Gray. A conversation with Jim Gray. ACM Queue, 1(4). ACM, June 2003.
[10] J. L. Griffin, S. W. Schlosser, G. R. Ganger, and D. F. Nagle. Modeling and performance of MEMS-based storage devices. ACM SIGMETRICS 2000 (Santa Clara, CA, 17-21 June 2000). Published as Performance Evaluation Review, 28(1):56-65, June 2000.
[11] J. L. Griffin, S. W. Schlosser, G. R. Ganger, and D. F. Nagle. Operating system management of MEMS-based storage devices. Symposium on Operating Systems Design and Implementation. (San Diego, CA, 23-25 October 2000), pages 227-242. USENIX Association, 2000.
[12] Hewlett-Packard Laboratories Storage Systems Program. https://www.hpl.hp.com/research/storage.html.
[13] B. Hong. Exploring the usage of MEMS-based storage as metadata storage and disk cache in storage hierarchy. https://www.cse.ucsc.edu/~hongbo/publications/mems-metadata.pdf.
[14] B. Hong, S. A. Brandt, D. D. E. Long, E. L. Miller, K. A. Glocer, and Z. N. J. Peterson. Zone-based shortest positioning time first scheduling for MEMS-based storage devices. International Workshop on Modeling, Analysis, and Simulation of Computer and Telecommunications Systems (Orlando, FL, 12-15 October 2003), 2003.
[15] Y. Lin, S. A. Brandt, D. D. E. Long, and E. L. Miller. Power conservation strategies for MEMS-based storage devices. International Workshop on Modeling, Analysis, and Simulation of Computer and Telecommunications Systems (Fort Worth, TX, October 2002), 2002.
[16] C. R. Lumb, J. Schindler, and G. R. Ganger. Freeblock scheduling outside of disk firmware. Conference on File and Storage Technologies (Monterey, CA, 28-30 January 2002), pages 275-288. USENIX Association, 2002.
[17] T. M. Madhyastha and K. P. Yang. Physical modeling of probe-based storage. IEEE Symposium on Mass Storage Systems (April, 2001). IEEE, 2001.
[18] N. Maluf. An introduction to microelectromechanical systems engineering. Artech House, 2000.
[19] The Millipede: A future AFM-based data storage system. https://www.zurich.ibm.com/st/storage/millipede.html
[20] R. Ramakrishnan and J. Gehrke. Database management systems, 3rd edition. McGraw-Hill, 2003.
[21] R. Ramamurthy, D. J. DeWitt, and Q. Su. A case for fractured mirrors. International Conference on Very Large Databases (Hong Kong, China, 20--23 August 2002), pages 430--441. Morgan Kaufmann Publishers, Inc., 2002.
[22] R. Rangaswami, Z. Dimitrijevic, E. Chang, and K. E. Schauser. MEMS-based disk buffer for streaming media servers. International Conference on Data Engineering (Bangalore, India, 5-8 March 2003), 2003.
[23] H. Rothuizen, U. Drechsler, G. Genolet, W. Haberle, M. Lutwyche, R. Stutz, R. Widmer, and P. Vettiger. Fabrication of a micromachined magnetic X/Y/Z scanner for parallel scanning probe applications. Microelectronic Engineering, 53:509-512, June 2000.
[24] C. Ruemmler and J. Wilkes. An introduction to disk drive modeling. IEEE Computer, 27(3):17-28, March 1994.
[25] J. Schindler and G. R. Ganger. Automated disk drive characterization. Technical report CMU--CS--99--176. Carnegie-Mellon University, Pittsburgh, PA, December 1999.
[26] J. Schindler, J. L. Griffin, C. R. Lumb, and G. R. Ganger. Track-aligned extents: matching access patterns to disk drive characteristics. Conference on File and Storage Technologies (Monterey, CA, 28--30 January 2002), pages 259--274. USENIX Association, 2002.
[27] J. Schindler, S. W. Schlosser, M. Shao, A. Ailamaki, and G. R. Ganger. Atropos: A disk array volume manager for orchestrated use of disks. Conference on File and Storage Technologies (San Francisco, CA, 31 March - 2 April 2004). USENIX Association, 2004.
[28] S. W. Schlosser, J. L. Griffin, D. F. Nagle, and G. R. Ganger. Designing computer systems with MEMS-based storage. Ninth International Conference on Architectural Support for Programming Languages and Operating Systems (Boston, Massachusetts), 13-15 November 2000. To appear.
[29] S. W. Schlosser, J. Schindler, A. Ailamaki, and G. R. Ganger. Exposing and exploiting internal parallelism in MEMS-based storage. Technical Report CMU-CS-03-125. Carnegie Mellon University, Pittsburgh, PA, March 2003.
[30] N. Talagala, R. H. Dusseau, and D. Patterson. Microbenchmark-based extraction of local and global disk characteristics. Technical report CSD-99-1063. University of California at Berkeley, 13 June 2000.
[31] B. D. Terris, S. A. Rishton, H. J. Mamin, R. P. Ried, and D. Rugar. Atomic force microscope-based data storage: track servo and wear study. Applied Physics A, 66:S809-S813, 1998.
[32] M. Uysal, A. Merchant, and G. A. Alvarez. Using MEMS-based storage in disk arrays. Conference on File and Storage Technologies (San Francisco, CA, 21 March-02 April 2003), pages 89-101. USENIX Association, 2003.
[31] P. Vettiger, G. Cross, M. Despont, U. Drechsler, U. Durig, B. Gotsmann, W. Haberle, M. A. Lantz, H. E. Rothuizen, R. Stutz, and G. K. Binnig. The "Millipede": nanotechnology entering data storage. IEEE Transactions on Nanotechnology, 1(1):39-55. IEEE, March 2002.
[34] B. L. Worthington, G. R. Ganger, and Y. N. Patt. Scheduling algorithms for modern disk drives. ACM SIGMETRICS Conference on Measurement and Modeling of Computer Systems. (Nashville, TN, 16-20 May 1994), pages 241-251. ACM Press, 1994.
[35] H. Yu, D. Agrawal, and A. E. Abbadi. Tabular placement of relational data on MEMS-based storage devices. International Conference on Very Large Databases (Berlin, Germany, 9-12 September 2003), pages 680-693, 2003.
[36] H. Yu, D. Agrawal, and A. E. Abbadi. Towards optimal I/O scheduling for MEMS-based storage. IEEE Symposium on Mass Storage Systems (San Diego, CA, 7-10 April 2003), 2003.
[37] H. Yu, D. Agrawal, and A. E. Abbadi. Declustering two-dimensional datsets over MEMS-based storage. UCSB Department of Computer Science Technical Report 2003-27. September 2003.
[38] X. Yu, B. Gum, Y. Chen, R. Y. Wang, K. Li, A. Krishnamurthy, and T. E. Anderson. Trading capacity for performance in a disk array. Symposium on Operating Systems Design and Implementation (San Diego, CA, 23-25 October 2000), pages 243-258. USENIX Association, 2000.
[39] C. Zhang, X. Yu, A. Krishnamurthy, and R. Y. Wang. Configuring and scheduling an eager-writing disk array for a transaction processing workload. Conference on File and Storage Technologies (Monterey, CA, 28-30 January 2002), pages 289-304. USENIX Association, 2002.
|
This paper was originally published in the
Proceedings of the 3rd USENIX Conference on File and Storage Technologies,
Mar 31-Apr 2, 2004, San Francisco, CA, USA Last changed: 17 March 2004 aw |
|