To affirm our methodology of using
![]() ,
,
![]() , and
, and
![]() as mostly stable measures of
password quality, we first plot these measures under various instances
of Assumption 4.1, i.e., for various values of
as mostly stable measures of
password quality, we first plot these measures under various instances
of Assumption 4.1, i.e., for various values of
![]() and, for each, a range of values for
and, for each, a range of values for
![]() . For example, in the case of
. For example, in the case of
![]() ,
Figures 3 and 4
show measures
,
Figures 3 and 4
show measures
![]() ,
,
![]() ,
,
![]() and
and
![]() , as well as the guessing entropy
as computed in (6), for various values of
, as well as the guessing entropy
as computed in (6), for various values of
![]() . Figure 3 is for the Face
scheme, and Figures 4 is for the Story
scheme.
. Figure 3 is for the Face
scheme, and Figures 4 is for the Story
scheme.
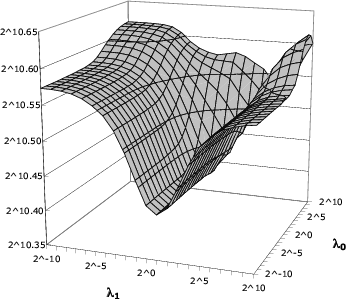
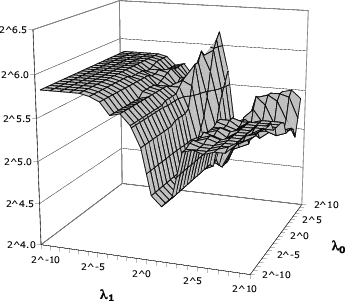
The key point to notice is that each of
![]() ,
,
![]() ,
,
![]() and
and
![]() is very
stable as a function of
is very
stable as a function of ![]() , whereas guessing entropy varies
more (particularly for Face). We highlight this fact to reiterate our
reasons for adopting
, whereas guessing entropy varies
more (particularly for Face). We highlight this fact to reiterate our
reasons for adopting
![]() ,
,
![]() , and
, and
![]() as our measures of security, and to set aside concerns
over whether particular choices of
as our measures of security, and to set aside concerns
over whether particular choices of ![]() have heavily influenced
our results. Indeed, even for
have heavily influenced
our results. Indeed, even for
![]() (with some degree of
back-off to
(with some degree of
back-off to
![]() as prescribed by (5)),
values of
as prescribed by (5)),
values of ![]() and
and ![]() do not greatly impact our
measures. For example, Figures 5 and
6 show
do not greatly impact our
measures. For example, Figures 5 and
6 show
![]() and
and
![]() for Face. While these surfaces may suggest more
variation, we draw the reader's attention to the small range on the
vertical axis in Figure 5; in fact, the
variation is between only 1361 and 1574. This is in contrast to
guessing entropy as computed with (6), which varies
between 252 and 3191 when
for Face. While these surfaces may suggest more
variation, we draw the reader's attention to the small range on the
vertical axis in Figure 5; in fact, the
variation is between only 1361 and 1574. This is in contrast to
guessing entropy as computed with (6), which varies
between 252 and 3191 when ![]() and
and ![]() are varied (not
shown). Similarly, while
are varied (not
shown). Similarly, while
![]() varies between 24 and 72
(Figure 6), the analogous computation
using (5) more directly--i.e., computing the smallest
varies between 24 and 72
(Figure 6), the analogous computation
using (5) more directly--i.e., computing the smallest
![]() such that
such that
![]() --varies between 27 and 1531. In the remainder
of the paper, the numbers we report for
--varies between 27 and 1531. In the remainder
of the paper, the numbers we report for
![]() ,
,
![]() , and
, and
![]() reflect values of
reflect values of ![]() and
and ![]() that simultaneously minimize these values to the
extent possible.
that simultaneously minimize these values to the
extent possible.
Tables 2 and 3 present results for the
Story scheme and the Face scheme, respectively. Populations with less
than ten passwords are excluded from these tables. These numbers were
computed under Assumption 4.1 for ![]() in
the case of Story and for
in
the case of Story and for ![]() in the case of Face.
in the case of Face.
![]() and
and ![]() were tuned as indicated in the table
captions. These choices were dictated by our goal of minimizing the
various measures we consider (
were tuned as indicated in the table
captions. These choices were dictated by our goal of minimizing the
various measures we consider (
![]() ,
,
![]() ,
,
![]() and
and
![]() ), though as already
demonstrated, these values are generally not particularly sensitive to
choices of
), though as already
demonstrated, these values are generally not particularly sensitive to
choices of ![]() and
and ![]() .
.
The numbers in these tables should be considered in light of the
number of available passwords. Story has
![]() possible passwords, yielding a maximum possible guessing
entropy of
possible passwords, yielding a maximum possible guessing
entropy of ![]() . Face, on the other hand, has
. Face, on the other hand, has ![]() possible
passwords (for fixed sets of available images), for a maximum guessing
entropy of
possible
passwords (for fixed sets of available images), for a maximum guessing
entropy of ![]() .
.
Our results show that for Face, if the user is known to be a male, then the worst 10% of passwords can be easily guessed on the first or second attempt. This observation is sufficiently surprising as to warrant restatement: An online dictionary attack of passwords will succeed in merely two guesses for 10% of male users. Similarly, if the user is Asian and his/her gender is known, then the worst 10% of passwords can be guessed within the first six tries.
It is interesting to note that
![]() is always higher
than
is always higher
than
![]() . This implies that for both schemes, there
are several good passwords chosen that significantly increase the
average number of guesses an attacker would need to perform, but do
not affect the median. The most dramatic example of this is for white
males using the Face scheme, where
. This implies that for both schemes, there
are several good passwords chosen that significantly increase the
average number of guesses an attacker would need to perform, but do
not affect the median. The most dramatic example of this is for white
males using the Face scheme, where
![]() whereas
whereas
![]() .
.
These results raise the question of what different populations tend to choose as their passwords. Insight into this for the Face scheme is shown in Tables 4 and 5, which characterize selections by gender and race, respectively. As can be seen in Table 4, both males and females chose females in Face significantly more often than males (over 68% for females and over 75% for males), and when males chose females, they almost always chose models (roughly 80% of the time). These observations are also widely supported by users' remarks in the exit survey, e.g.:
``I chose the images of the ladies which appealed the most.''
``I simply picked the best lookin girl on each page.''
``In order to remember all the pictures for my login (after forgetting my `password' 4 times in a row) I needed to pick pictures I could EASILY remember - kind of the same pitfalls when picking a lettered password. So I chose all pictures of beautiful women. The other option I would have chosen was handsome men, but the women are much more pleasing to look at :)''
``Best looking person among the choices.''
Moreover, there was also significant correlation among members of the same race. As shown in Table 5, Asian females and white females chose from within their race roughly 50% of the time; white males chose whites over 60% of the time, and black males chose blacks roughly 90% of the time (though the reader should be warned that there were only three black males in the study, thus this number requires greater validation). Again, a number of exit surveys confirmed this correlation, e.g.:
``I picked her because she was female and Asian and being female and Asian, I thought I could remember that.''
``I started by deciding to choose faces of people in my own race ... specifically, people that looked at least a little like me. The hope was that knowing this general piece of information about all of the images in my password would make the individual faces easier to remember.''
``... Plus he is African-American like me.''
Insight into what categories of images different genders and races chose in the Story scheme are shown in Tables 6 and 7. The most significant deviations between males and females (Table 6) is that females chose animals twice as often as males did, and males chose women twice as often as females did. Less pronounced differences are that males tended to select nature and sports images somewhat more than females did, while females tended to select food images more often. However, since these differences were all within four percentage points, it is not clear how significant they are. Little emerges as definitive trends by race in the Story scheme (Table 7), particularly considering that the Hispanic data reflects only two users and so should be discounted.