| ||||||||||||||||||||||||||||||||||||||||||||||||||||
USENIX Symposium on Internet Technologies and Systems, 1997
[Technical Program]
SASE : Implementation of a Compressed Text Search EngineSrinidhi Varadarajan Tzi-cker Chiueh Department of Computer Science (srinidhi, chiueh)@cs.sunysb.edu http://www.ecsl.cs.sunysb.edu/RFCSearch.html
Abstract Keyword based search engines are the basic building block of text retrieval systems. Higher level systems like content sensitive search engines and knowledge-based systems still rely on keyword search as the underlying text retrieval mechanism. With the explosive growth in content, Internet and Intranet information repositories require efficient mechanisms to store as well as index data. In this paper we discuss the implementation of the Shrink and Search Engine (SASE) framework which unites text compression and indexing to maximize keyword search performance while reducing storage cost. SASE features the novel capability of being able to directly search through compressed text without explicit decompression. The implementation includes a search server architecture, which can be accessed from a Java front-end to perform keyword search on the Internet. The performance results show that the compression efficiency of SASE is within 7-17% of GZIP one of the best lossless compression schemes. The sum of the compressed file size and the inverted indices is only between 55-76% of the original database while the search performance is comparable to a fully inverted index. The framework allows a flexible trade-off between search performance and storage requirements for the search indices. 1.0 Introduction Efficient search engines are the basic building block of information retrieval. Content sensitive engines like Lycos and Yahoo still rely on keyword search as their underlying search mechanism. Furthermore, with growth in corporate intranet information repositories, efficient mechanisms are needed for information storage and retrieval. In this paper we propose a scheme to maximize keyword search performance while reducing storage cost. The basic idea behind the proposed framework called the Shrink and Search Engine (SASE), is to use the commonality between dictionary coding and inverted indexing to unite compression and text retrieval into a common framework. The result is a search engine that is efficient both in terms of raw speed as well as storage requirement, and has the capability of searching directly through compressed text. This paper is organized as follows. Section 2 describes the basic idea behind SASE. In section 3 we discuss the implementation issues and our Internet SASE Server architecture. Section 4 reports the results of a performance analysis of our system. In section 5, we present related work in the area. Section 6 concludes the paper with a report on the major results and future work in the area The common approach to fast indexing uses a structure called the inverted index. An inverted index records the location of each word in the database. When a user enters a query word, the inverted index is consulted to get occurrence list of the word. Typically the inverted index is maintained as a dictionary with a linked list of occurrence pointers associated with each word. The dictionary is organized as a hash table for faster keyword search. A significant characteristic of textual data is the high degree of inherent redundancy in it. Text compression reduces source redundancy by substituting repetitive patterns with shorter numerical identifiers. Text compression can be done by variable bit length statistical schemes like Huffmann coding or dictionary based schemes like LZW, which substitute identical character strings with dictionary identifiers representing the pattern. Our observation here is, that both inverted indexing and dictionary based text compression require a dictionary. Hence one can reuse the dictionary from the inverted index for dictionary coding uniting compression and pattern matching into a common framework. Dictionary based compression can be done at several levels of token granularity. In our united compression/pattern matching framework, we use a word as the basic dictionary element. A word is any pattern punctuated by white-space characters. The advantage of this approach is that it integrates the requirements of word based pattern matching and compression. The drawback is that the compression efficiency is not as high as that obtained from dictionary schemes like Lempel-Ziv which use arbitrary string tokens. Text compression is performed in SASE by substituting words with their numerical representation called lexical codes. To improve the utilization efficiency of the available lexical code space, we use a technique similar to Huffmann coding at the byte level. The set of words in a database is partitioned into three groups viz. common words, uncommon words and literals. Common words occur more frequently than uncommon words, which in turn occur more frequently than literals. The classification is done on the basis of the compression benefit factor (CBF) of a word, which is defined as the product of the length of the word and its occurrence count. This partitioning is done off-line since the target applications for this scheme are mainly read-only databases. In the common word dictionary, words are represented by a 1 byte code. The uncommon word and literal dictionaries use a 2 byte code. Our experiments show that comm! on words occur more than 50% of t
2.1 Compression and Decompression In order to compress a text database, the database is first scanned to determine the list of unique words sorted by their compression benefit factors. The first 256 words are put in the common word dictionary and the next 64K words are put in the uncommon word dictionary. The second pass is done during the compression phase where each word in the database is converted to its dictionary id. In this pass literals are identified and literal dictionaries are created on demand. This scheme allows us to share the common and uncommon word lists across multiple similar databases. Compression on such databases would need only one pass. The compressed representation of a text file consists of the following four files:
The number of unique words found in normal databases (stories, newspaper articles etc.) is quite small. However, technical databases tend to have a very large vocabulary, particularly when they contain computer program code or ASCII art. To accommodate these words, SASE reserves code space in the common word file to support up to 10 literal word dictionaries of 64K words each for a total of 704K words. More codes may be reserved to support larger databases at a small penalty in compression ratio due to the increased number of reserved tokens. In a full inverted index structure, each dictionary entry consists of a linked list, which records the positions of all instances of the word. When the user enters a keyword, the linked list is followed to obtain all the occurrences of a keyword. While this scheme has very fast search times, the space complexity of generic full inverted indexing schemes is quite large. The size of the inverted index has been reported to range between 50%-300% of the size of the original database[FALO85]. SASE solves this problem by using an indexed approach. The text database is partitioned into blocks by partitioning the bitmap file into equal sized chunks. The pointers in the linked list are block identifiers. Note the partitioning is in terms of bits in the bitmap file, for example a 4KB block size contains 4K*8 = 32K words. The first occurrence of a keyword in each block is recorded irrespective of the number of occurrences of the keyword in the block. In order to reach the other occurrences, a linear search is performed on the block. This scheme allows a flexible trade-off between speed and storage requirement. With a smaller block size, it takes less time to search through it, whereas the space requirement increases since there are more block pointers. Conversely, a larger block size requires less block pointers whereas the time required for searching is larger. In the indexed approach taken by SASE, we need to perform a linear search in a block to find other instances of a keyword. A naïve implementation would decompress the compressed text and perform string comparisons between the query word and the decompressed text. Since SASE applies dictionary coding in its compression scheme, it is possible to search directly through the compressed text without explicit decompression. The query keyword is first converted into its dictionary id and directly compared against the dictionary id’s in the compressed text. When an instance of the keyword is found, the location in the compressed files is marked. Future searches can begin from this location. Search within a block is terminated when the number of instances of the keyword found matches the count field associated with a block, which maintains the total number of occurrences of the keyword. This scheme is much faster! than any string comparison basedBoolean queries can be performed by AND/OR operations on the linked lists associated with the query keywords. The resultant list formed by the applying the Boolean expression on the linked lists is then searched. The block size of the inverted index plays a critical role in the performance of SASE. An optimization that can be performed here is to use different block sizes for different words. SASE implements a fully indexed dynamic index cache to reuse results from previous searches. A separate dictionary is used which caches every occurrence of the most frequently/most recently accessed words. When a keyword is searched, the search results are posted to the index cache. Since SASE supports next occurrence type of queries, it is possible to have incompletely filled entries in the index cache. These incompletely filled entries are filled when a user query accesses all occurrences of a keyword. The index cache is consulted to see if it can satisfy a request before beginning a search using the inverted index.2.3 Approximate Search For approximate searching, the set of uncommon words and literals are statically organized in a Vantage Point (VP) [YIAN92][CHIU94] tree. The user specifies the desired maximum number of errors between the query word and his results. We can then traverse the VP tree to get a set of words that fall within the allowable error range. The set of allowable branches is determined by comparing the query word against the interior nodes of the tree. The remaining branches are pruned since we know that none of their leaf nodes can contribute to the query. Although this scheme performs considerably better than a linear search through the dictionary, the number of comparisons is still high. An interesting observation here is that word lengths are finite and discrete. Hence, we can build multiple VP trees, one for each length.. When the user enters a query, the set of allowable VP trees is determined from the length of the query word and the desired maximum number of errors. These VP trees are then searched to get the set of allowable words. Experiments on this scheme show that we need to compare against 4-8% of the words in the dictionary to get the set of allowable words. After the allowable set of words has been determined, we search the database for each word in the set. The ITCI compression/search engine has been implemented in C running on a UNIX platform. It is consists of a (i) compression and decompression engine and (ii) a search engine. In our current implementation of SASE, we have built a communication subsystem around the search engine to allow searches from the World Wide Web using a Java front-end. In this section we discuss implementation details of the various sub-systems within SASE. Before we begin compression, we need to collect statistics to determine the word breakup into common words; uncommon words and literals based on the compression benefit factor. Once these statistics are collected, the compression engine builds up a hash table of common words and uncommon words. Literal hash tables are created on demand whenever they are encountered in the text. In this phase we also build an inverted index for uncommon words. Literal inverted indices are created on demand. After the indices have been built, a parser parses the input token stream to extract words from it. Words are defined as a stream of alphanumeric characters delimited by white space tokens. Several optimizations are performed in this phase.
An added feature of the compression engine is its 3.2 Search Engine The basic operation of the search engine is quite simple. When the user enters a keyword for searching we execute a hash based search function on it. If the keyword is found, the hash table returns the classification (common word, uncommon word or literal) and its numerical representation. Once we have the numerical code, we can index into the inverted index to get the linked list of pointers to occurrences of the keyword.Since the inverted index is usually quite large, it is maintained on disk. When a keyword is found in the hash table, the corresponding inverted index entry is retrieved from disk. We have a block marker file associated with each compressed database, which marks the positions of the file pointers to the common word uncommon word and literal files at the start of each block. To locate the first instance of a keyword, we go through the linked list to obtain the pointer to the block containing the keyword. Based on the information from the block marker file, we reposition the file pointers to the start of a block and perform a linear search to locate the keyword.Typical queries ask for the first occurrence of a keyword, the next occurrence and so on based on the results obtained. A naive way to implement this would be to continue searching within the block till the occurrence number required by the user is found. For e.g. if user requests the third occurrence of aardvark, we search the block until we hit the third occurrence, ignoring the first two occurrences. While this solution works, it is hardly optimal. In order to handle next occurrence kind of queries, we need maintain positional metadata on the previous location where the keyword was found. If we need to find the next occurrence of the keyword, we use this to reposition our start of search location. This solution allows us to perform incremental searching within a block with minimal time overhead. After an instance of the keyword is found, we know the locations within the common word, uncommon word and literal files. We then backtrack on the common word, uncommon word and literal files till we can decompress a block of text (200 words in our case) around the occurrence and return it to the user. The backtracking algorithm is complicated by the fact that tokens in the common word file cannot be interpreted in the reverse order since there may be run length encoded tokens. Another complication is that we need to look out for document boundaries during the backtrack phase. In our scheme, backtracking is performed by using a lookback buffer for the common word file. This ensures that the numerical codes are interpreted correctly. The lookback buffer is not needed for the uncommon word and literal word files since these codes can be interpreted correctly in both directions.3.3 Search Server Architecture In our current implementation of the search engine, we have incorporated a communication sub-system, which allows queries to the search engine from the World Wide Web using a Java front-end. Communication is done using sockets opened between the Java client and the search server. For each query from a client, the server forks a copy of itself to perform the actual search and return the results. The server itself does a "busy wait" waiting for connections. The advantage of this scheme is that we use the semantics of the fork call to transfer the cache to the child process without performing a data copy. Most current UNIX systems implement the copy-on-write protocol. This reduces the overhead of the fork call. While this scheme allows a search child to see the same cache as the server, we need a mechanism to update the cache on the server when! the child finds a new occurrenceAs mentioned earlier in this section, we need to maintain file position metadata after each keyword search to optimize next occurrence queries. . We use a novel scheme to maintain this metadata. In the SASE server architecture, the Java clients who send in this information with each next occurrence query maintain this metadata. The major implication of this scheme is that the server is now stateless, since each client knows its version of the server state.
Figure 2 : Execution of a typical search query from then Web. The Java client sends in its query to the SASE super server, which forks a copy of itself to perform the search. The child process returns the result to the client along with server metadata. The child also performs a cache update on the super server.
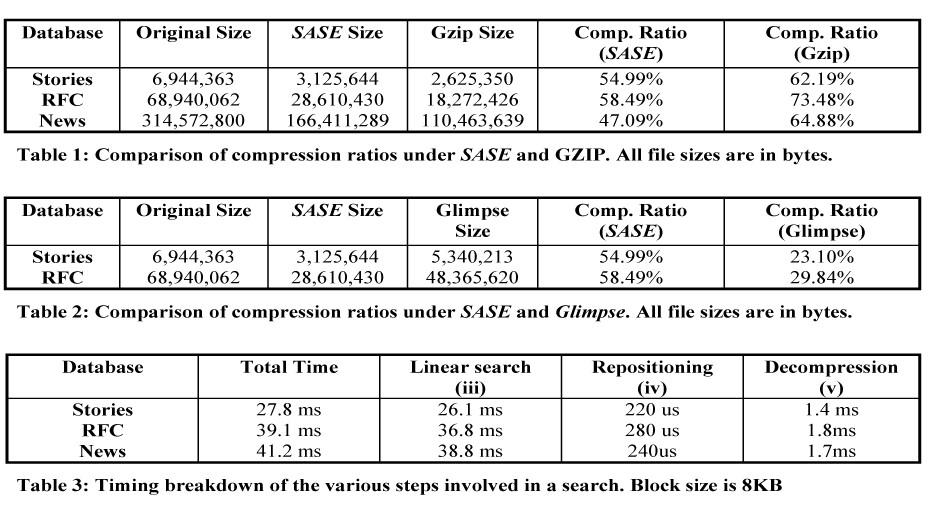
In our Web communication model, the Java clients open a TCP socket to the server and send in their query and the server metadata. To prevent the clients from using up all the server connections, the socket is closed once the search engine returns its results. The small lifetime of sockets combined with the stateless nature of the server allows us to shut down the server and bring it up again without any noticeable difference to the clients. This is an attractive feature for administrative purposes. The downside of this scheme is that if the search database is updated, then the metadata on all the clients has to be updated as well. Since the clients close the socket once they get a response, we have no way of intimating them of changes in the server since we don’t know who the clients are. This is solved by in a novel way. The compression engine generates a set of checksums when it compresses a database. These checksums are sent to the clients when they! first query the server and the cIn this section we report the results of a performance evaluation of the SASE prototype and an analysis of the results. To evaluate our compression efficiency, we compare SASE against GZIP one of the best lossless compression utilities. We also present the search performance numbers of SASE. To ensure a representative text database, we chose three large text databases each representing of a certain vocabulary. The first database consists of 7 MB of stories from Project Gutenberg. This represents everyday literary English usage. The second database contains the Internet RFC documents. This 70MB database represents technical vocabulary from a particular field, in this case networking. The third database consists of 300MB of USENET news articles from several different newsgroups from different newsdomains like alt, rec, misc and comp. This database contains vocabulary from a wide variety of domains. 4.1 Compression Performance Table 1 compares the compression ratios of SASE and GZIP. Compression ratio is defined as: The differences range between 7 and 17%. Although both SASE and GZIP are based on dictionary coding, GZIP can choose arbitrary length strings as candidate tokens for compression. Since SASE is limited to choosing strings demarcated by white spaces as tokens it suffers a performance penalty in compression. This performance gain in GZIP is more marked in the News and RFC databases, which have a more dynamic vocabulary.
4.2 Search performance Execution of a search query under SASE involves (i) finding the numerical representation of the query keyword (ii) locating the first block containing the keyword (iii) performing a linear search to get the exact location of the keyword (iv) reposition of file pointers to begin decompression and (v) decompressing and transmitting the result back to the client. Steps (i) and (ii) are trivial and take much less time compared to the linear search required to locate the keyword within a block. Table 3 shows the timing breakdown of the various steps involved in a search.
Figure 1: Effect of varying block size on the search overhead and query response time for the RFC database. Block size is varied betwen 2KB and 32KB. As we mentioned in Section 2.2, by varying the block size, SASE allows a trade off between search time and index space overhead Figure 3 shows the effect of varying the block size on the RFC database. The index space overhead consists of the space taken up by the inverted indices for the uncommon word and literal dictionaries. The query search times were measured by searching for 10,000 random keywords and the runs were repeated for block sizes between 2KB and 32KB. Search times vary between 13ms to 120ms which compares favorably with a fully inverted index scheme. In [MOFF95][WITT94] [ZOBE95], Moffat and Zobel describe a word based lossless compression scheme which uses a fully inverted search index. The database is divided into files and compressed using Huffmann coding. Given a keyword, the inverted index is searched to get the linked list of occurrences. The portions of the file containing the keyword are then decompressed and sent to the user. Since this scheme uses a fully inverted index, the space taken up by the inverted index is much larger than SASE. Decompression speed is also slower than SASE due to the bit level manipulation that is required for decompressing Huffmann coded files. Variants of this scheme partition the database into blocks and compress the blocks using gzip. These schemes maintain inverted index pointers to blocks rather than every occurrence of a keyword. While these schemes have very good compression ratios, they need to decompress a block before searching! through it. This operation incre The two step indexed approach taken by SASE is very similar to Glimpse [MANB94a][MANB94b]. Table 2 compares the compression efficiency of SASE and Glimpse (version 4.0) on both natural language text and technical documents. The difference in compression efficiency ranges between 28-31%. At the setting for the fastest search performance, the glimpse inverted index is 10% larger than SASE for comparable search times. SASE also optimizes the two level approach with an index cache of dynamic block size which allows to use a large block size for space savings while retaining the speed advantages of a smaller block size. On the other hand, glimpse does better job in the choice of keywords to index. The approximate pattern matching algorithm in glimpse (agrep) is also more powerful than the simple keyword search mechanism of SASE. Since our VP tree based, approximate keyword match framework takes the string ! comparison function as a black bo There are also several theoretical studies [AMIR96][FARA95] which discuss algorithms for searching through Lev-Zempel files. However, these schemes have not been implemented for us to make a fair comparison.In this paper, we described a text search engine called SASE, which operates in the compressed domain. It provides an exact search mechanism using an inverted index and an approximate search mechanism using a vantage point tree. Secondly it allows a flexible trade-off between search time and storage space required to maintain the search indices. The results of our experiments show that the compression efficiency is within 7-17% of GZIP, which is one of the best lossless compression utilities. The sum of the compressed file size and the inverted indices is only between 55-76% of the original database, while the search performance is comparable to a fully inverted index.We are currently working on the implementation of the approximate search mechanism using a vantage point tree. Another area of work is to use SASE as the underlying file system for NNTP servers. This gives NNTP servers the capability to perform keyword searches through USENET archives. When this system is up, it would yield important results on the choice of a cache replacement policy for the SASE dynamic index cache. While incremental additions to the compressed database are permitted in an inverted index based search system, the database is assumed to be mainly read-only. We are working on an indexing mechanism that would effectively remove the read-only restriction and allow the user to make real time changes to the database without having to recalculate the inverted indices. This scheme can be used for document management servers within companies and for maintaining the web page index database in Internet search ! engines like Lycos and AltaVista.
References [AMIR96] Amir, A., Benson, G., Farach, M.; "Let sleeping files lie: pattern matching in Z-compressed files", [BLUMER87] Blumer A., Blumer J.; "On-Line Construction of a Complete Inverted File", [BLUMER84] Blumer A., Blumer J., Ehrenfeuchter A., Haussler D., McConnell R.; "Building a Complete Inverted File for a Set of Text Files in Linear Time", [CHIU94] Chiueh T.; "Content-based image indexing" [EVEN78] Even S., Rodeh M.; "Economical Encoding of Commas Between Strings", [FARA95] Farach, M., Thorup, M.; "String matching in Lempel-Ziv compressed strings", [FALO85] Faloutsos, C.; "Acccess methods for text", [FRAENKEL83] Fraenkel A.S., Mor M.; "Is Text Compression by Prefixes and Suffixes Practical", [KNUTH85] Knuth D.E.; "Dynamic Huffman Coding", [KNUTH77] Knuth D.E. Morris J.H., Pratt V.R.; "Fast Pattern Matching in Strings", [LEMPEL77] Jacob Ziv, Abraham Lempel; "A Universal Algorithm for Sequential Data Compression", [MANB94a] Manber, U.; "A text compression scheme that allows fast searching directly in the compressed file", [MANB94b] Manber, U., Sun Wu; "GLIMPSE: a tool to search through entire file systems", [MCINTYRE85] McIntyre D.R., Pechura M.A.; "Data Compression using Static Huffman Code-Decode Tables", [MOFF95] Moffat, A., Zobel, J.; "Information retrieval systems for large document collections", [PIKE81] Pike J.; "Text Compression using a 4-bit Coding Scheme'', [STORER87] Storer J.A., Tsang S.K.; "Data Compression Experiments Using Static and Dynamic Dictionaries", [WAGNER73] Wagner R.A.; "Common Phrases and Minimum-Space Text Storage", [WITT94] Witten, I., Moffat, A., Bell, T.; "Managing Gigabytes", [YANNAKOUDAKIS82] Yannakoudakis E.J., Goyal P., Huggil J.A.; "The Generation and Use of Text Fragments for Data Compression", [YIAN92] P. Yianilos; "Data structures and algorithms for nearest neighbor search in general metric spaces", [ZOBE95] Zobel, J., Moffat, A.; "Adding compression to a full-text retrieval system",
|
|
This paper was originally published in the
Proceedings of the USENIX Symposium on Internet Technologies and Systems,
December 8-11, 1997,
Monterey, California, USA
Last changed: 12 April 2002 aw |
|