
For comparison, we implemented a ``centralized'' version of SWORD in which
each update is sent to one of ![]() servers at random, and each query is
sent to all
servers at random, and each query is
sent to all ![]() servers. We chose the servers to be machines with low load
and low latency/high bandwidth network links. In contrast, the nodes
used to satisfy a query in the DHT approach are selected randomly, since
nodes choose their DHT IDs randomly.
servers. We chose the servers to be machines with low load
and low latency/high bandwidth network links. In contrast, the nodes
used to satisfy a query in the DHT approach are selected randomly, since
nodes choose their DHT IDs randomly.
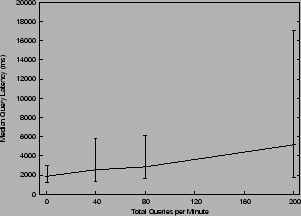 |
Figure 2 shows the performance of the DHT range search as a function of query rate. We emphasize that these experiments were conducted over a 4-hour period during which node and network resource contention varied, and the number of nodes in the system varied slightly. These results are therefore only approximately repeatable. For comparison, the ``centralized'' version with one server offered consistently inferior median performance for query rates of 40 queries/min and above (ranging from median latency of 728 ms for 1 query/min to 12.5 seconds for 200 queries/min), while the ``centralized'' version with two servers offered consistently superior median performance for all query rates (with median latency ranging from 251 ms for 1 query/min to 3.3 seconds for 200 queries/min). This suggests that although DHT-based SWORD may offer acceptable performance, a non-DHT-based version with as few as two well-chosen servers may offer superior performance. The general lesson here is that users deploying services intended for the scale of PlanetLab might be wise to consider implementing a simpler ``centralized'' version first, only moving to a decentralized design if they believe it will substantially improve some property of the service.
Our next experiment examined optimizer latency as a function of number of candidate nodes, for a query that requested two groups of nodes, 4 nodes in each group, with at most 150 ms inter-node latency within each group, and all nodes with a varying range of loads ranges that allowed us to control the number of candidate nodes returned. This experiment showed that even under moderately high load (the optimizer was run on a node with a load consistently in the 3-4 range, with over two dozen active slices), and with the worst case of all nodes returned by the distributed query as candidate nodes, the optimizer could satisfy the query in less than seven seconds. Still, this performance is somewhat disappointing, suggesting that we should attempt to improve the optimizer's performance and should consider moving the computation entirely to the (presumably less loaded) user's machine rather than running it on the PlanetLab node that servers as the query's entry point into SWORD.
Jeannie Albrecht 2004-11-03