We have four years of experience running a cloud native, agile platform that supports Greek government services. In this article, we describe the platform and its different components for managing containers, networking, monitoring, and checking security. Furthermore, through a number of use cases we highlight the platform’s capabilities and finally, describe our experiences from production.
The Greek National Infrastructures for Research and Technology (GRNET), is the Greek NREN (National Research and Education Network). GRNET provides networking, cloud computing and services to academic and research institutions [1,2]. In 2019, GRNET became highly involved with the digital transformation of the Greek public sector. Specifically, operating under the auspices of the Ministry of Digital Governance, the organization became responsible for the development, operation and maintenance of the gov.gr portal (Greece’s public sector information website) and several governmental services including the electronic issuance of documents signed by the Greek state, and a digital wallet that Greek citizens can use to control how they share identification data among others. Τhe advent of the COVID-19 pandemic made the implementation and maintenance of these services more urgent and critical.
Offering services for the general public of a country introduces a set of challenges and considerations that differ from those associated with services targeted at the academic community. Some key issues involve:
- Faster development and deployment cycles: the initial goal was to launch a number of services in a short period of time. Additionally, we expected continuous feedback (based for instance on new legislative amendments) that should be immediately reflected in the services that were already up and running. Thus, a renewed, faster development cycle was required.
- Scalability and resiliency: governmental services need to handle a large number of concurrent users and scale to accommodate potential growth. The corresponding infrastructure and technologies should be scalable to ensure that the services remain responsive and available, especially during peak usage times.
- Security: services for the general public require robust security mechanisms that protect against attacks that attempt to disrupt normal traffic (Distributed Denial of Service attacks) or application layer attacks such as Cross-site Scripting (XSS).
- Public Perception and Reputation: the success of governmental services is often tied to public perception and trust. Indeed, when citizens trust that their interactions with such services are reliable and efficient, and that their personal data are handled in a secure manner, they are more likely to use them. Thus, maintaining transparency, effective communication, and promptly addressing issues contribute to building and preserving a positive reputation for the organization. This helps promote best practices for users and organizations alike.
Τo cope with their new duties and demands, GRNET teams including primarily the SRE (Site Reliability Engineering) team, developers and the security team, developed AppStack, a cloud-native platform with an enabling environment for integrating open-source software (OSS) components. Currently, AppStack is maintained by GRNET’s SRE team and hosts more than 200 user flows for governmental services. In the following, we will describe AppStack, its infrastructure, and highlight the significance of its different components through a number of use cases.
Through AppStack, technical teams work together based on a common pipeline with different capabilities that support agile software development practices and provide a faster release pace — see Figure 1. The pipeline starts with the developers working on software artifacts using GitLab CI ⓵. By using GitLab CI, developers are able to collaborate, manage repositories, track issues, and apply Continuous Integration (CI) practices. Once they have finished an application version that is ready for production, they generate a corresponding container. Containers include all the elements needed to run a software artifact such as the application code, its dependencies, configuration files, operating system libraries and more. All container images are then placed in Harbor ⓶, a container registry that offers a way to process (e.g. scan for security issues) and distribute such images.
To deploy and operate corresponding containers, we utilize Kubernetes (K8s) ⓸, a well-established container-orchestration system. K8s comes with a number of key properties. First, to partition and isolate resources within a cluster, K8s uses namespaces. Note that namespaces can be used to create virtual clusters within a single physical cluster, allowing different applications to share the physical cluster without interfering with each other. A namespace can contain multiple services. A K8s service is an abstraction that defines a set of pods, i.e. the smallest deployable unit in K8s. Services enable communication between different application components and pods represent a single instance of a running process in the cluster. A pod may contain multiple containers that share network and storage resources and are managed together. The central management component of K8s is the control plane. The control plane manages the cluster's state through its different mechanisms. Such mechanisms include a distributed key-value store (etcd) that contains the cluster’s configuration data and state information, a scheduler that evaluates resource requirements and distributes the workload, and an API server that allows teams to interact with the system via a set of specific API calls.
We simplify the process of deploying, managing, and upgrading applications on Kubernetes by using Helm ⓷. Helm provides means to package applications into reusable, shareable packages called charts. A chart contains all resource definitions and associated configurations needed to deploy a specific application. Furthermore, Helm charts support versioning, thus enabling our teams to roll back to previous versions in case of failures and ensure reproducibility and consistency in deployments. AppStack also incorporates a complete monitoring stack ⓹ which includes Sentry, an error tracking framework that helps developers identify, diagnose, and resolve programming issues, the Prometheus alerting toolkit, and the EFK (Elasticsearch, Fluentd, and Kibana) suite that offers log management, visualization and analysis capabilities.
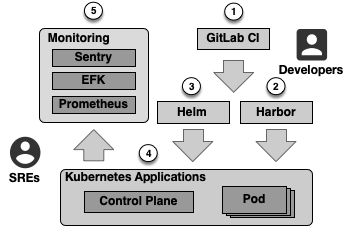
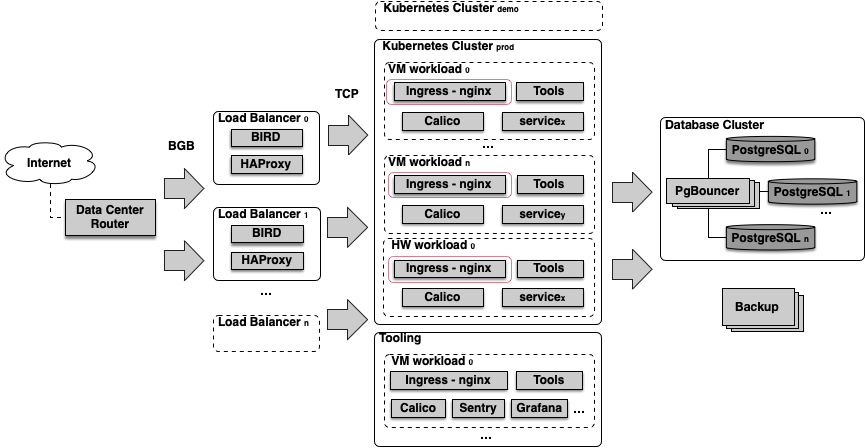
Figure 2 presents the AppStack infrastructure. Internet traffic reaches GRNET’s Data Center (DC) as seen on the left side. The DC router forwards the traffic to the Load Balancers (LBs) that stand in front of the Kubernetes clusters. The communication between the router and the LBs is done by using the Border Gateway Protocol (BGP). This provides us with a number of advantages, namely flexibility, because BGP supports advanced features such as policy-based routing and traffic engineering, and fault tolerance, since BGP supports dynamic route selection and failover mechanisms. To establish BGP connections with the router, our load balancers use BIRD, a robust and scalable routing software package which is supported by an active community. In practice, every service (e.g. www.gov.gr) has its own IP address which is advertised by the LBs to the DC routers and then to the core routers of GRNET’s backbone network.
To distribute the incoming network traffic across the clusters, the LBs use HAProxy (High Availability Proxy). HAProxy comes with a number of key features including throttling capabilities to control the rate of incoming request to prevent abuse and dynamic configuration allowing SREs to change load balancing methods on the fly. Note that HAProxy operates as a TCP proxy and does not handle HTTP requests.
On the clusters’ side, the Ingress-NGINX controllers that exist in every workload running as pods, receive and manage traffic. Specifically, they terminate TLS connections and specify how incoming requests should be handled, including hostnames, paths, and backend services. Notably, the controllers incorporate built-in mechanisms for load balancing across different backend services and automated TLS certificate handling. To secure our services from application attacks, we have also integrated the ModSecurity Web Application Firewall (WAF) as an additional layer of Ingress-NGINX (the thin red layer wrapping Ingress-NGINX in Figure 2). Note that technical teams can enable this feature through the Helm chart of the service they intend to protect. To handle traffic inside clusters we use Calico, a networking solution for containerized workloads. Calico uses BGP to handle large numbers of routes making it suitable for such large-scale deployments.
Each cluster may include both Virtual Machines (VMs) and hardware nodes, which in turn, host different workloads. Apart from the clusters that host the various services, there is also a separate cluster where we host the various components of the pipeline we discussed earlier. These components are available only through VPN to authorized personnel. Also, the LBs that send traffic to this particular cluster are not the same with the ones that distribute traffic to the clusters that host public services.
All data is stored in a separate database cluster. As a backend database we use PostgreSQL. PostgreSQL is a relational database management system that employs sophisticated concurrency control mechanisms and indexing capabilities to optimize query performance. To improve the performance and scalability of our databases we utilize PgBouncer. PgBouncer is a connection pooler that acts as a middle element between applications and database servers pooling and reusing connections to serve multiple client requests. To do so, it maintains a pool of pre-established connections to the database servers and assigns connections to clients on-demand, reducing the overhead of establishing new connections and improving overall database performance.
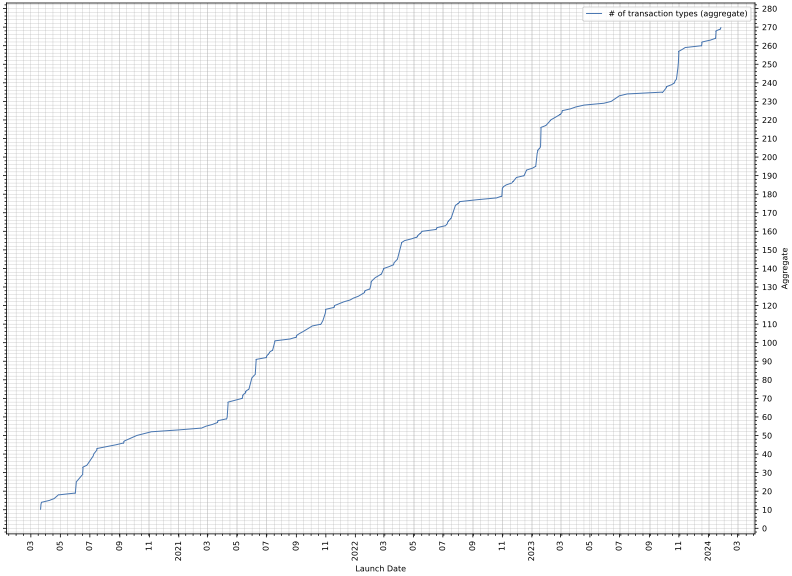
Over the past 4 years over 200 kinds of governmental transactions have been implemented based on our infrastructure. As we mentioned earlier, hosted services include the gov.gr portal and the electronic issuance of documents signed by the Greek state. Such documents involve affirmations, authorizations, notarization of the Hague (e-apostille) and EU certificates related to COVID-19 (e.g. vaccination) among others.
Up until now, 8.3M distinct citizens have been served, and ~275M transactions have been performed. A transaction usually takes 2 to 4 minutes where a user interacts with a service to issue a document signed by the state. Such transactions include authorizations, user input provisions, preview / consent actions and PDF downloads. Figure 3, presents the aggregate number of the different transaction types that have taken place throughout the years using AppStack. Note that the sharp increases in the number of transactions usually coincide with the launch of a new service.
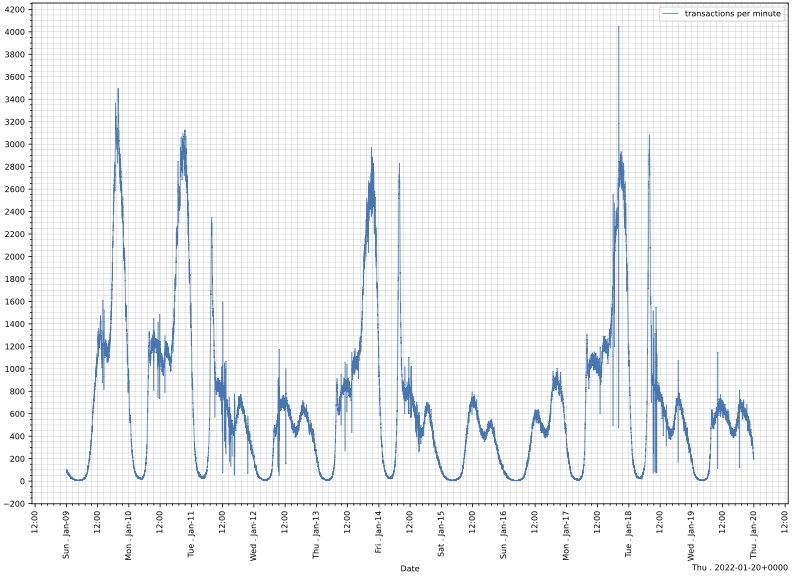
During peak hours our infrastructure is able to deal with 20K requests per second and yield up to 6500 documents per minute (~100 per second). Figure 4 presents the 10 most busy days that AppStack has ever encountered. During this period, i.e. January 2022, Greece was under lockdown and every two days, Greek students had to generate COVID-related documents and report them to their corresponding schools. Usually, this took place during the afternoon as seen in the sudden increases where a significant influx of visitors appeared in a short period (3-4 hours). During these days, AppStack was supporting the generation of more than 1.7 million documents per day.
AppStack has been running in production since February 2020. Our current production setup involves 50 bare metal servers, 150 VMs, 900 pods, and ~50 TB of storage. After 4 years in production we have several notable experiences which we enumerate below.
AppStack and its scalable architecture, allows for multiple deployments per day, even with thousands of users connected. Based on this set up, we are able to respond to changing conditions and feedback quickly, adapt to user needs and release new features and updates. Furthermore, through fast hotfix deployment times we are able to minimize the impact of a severe issue or bug in our production systems by swiftly implementing and deploying a solution. Notably, during the COVID-19 pandemic, the policies that were related to the various services running on AppStack, were decided in a national operations room and communicated by phone to the technical teams, which in turn implemented corresponding changes and deployed the updated services within minutes.
Our monitoring stack helped us in various situations. By carefully monitoring different metrics such as request / response times, success rates, connection pool usages, time-out rates and database CPU / disk usage during heavy traffic, we were able to tune parameters including the number of application workers and container pods, database connection timeouts and pool size and memory cache sizes among others, to keep the system from reaching several bottlenecks (e.g. database I/O limits, concurrent HTTP and database connections and more). At some point, during an abrupt and substantial increase in the number of users, our monitoring system could not process corresponding metrics and collapsed. However, the services continued to run successfully because they were decoupled by design and ran isolated from each other.
There are third-party government services that run on other infrastructures and interoperate with the services hosted on AppStack. On numerous occasions, managers responsible for these third-party services, notified us that their services could not handle the increasing traffic. To manage such situations, we regulated traffic through our platform, absorbing and delaying incoming user requests to keep the third-party services functional.
Notably, our infrastructure setup enabled us to keep all services up and running during a 48-hour data center shutdown that occurred due to extensive electrical work. To do so, we provided power only to the infrastructure (network, computing and storage) that is utilized to host our platform.
All services are constantly under attack according to our WAF reports. For instance, in September 2023 our WAF identified various attacks (27.5K requests in total) including different Cross-site Scripting (XSS) attack types, SQL injection and others, coming from 10 different countries. Furthermore, our platform enables the periodic scanning of container images via open-source scanners (e.g. Trivy) to identify and address security vulnerabilities in container images early in the development lifecycle.
To conclude, our experience from running AppStack indicates that it has great potential. Our plan is to expand the platform as more services are scheduled. Currently, we are working on disaster recovery solutions to replicate data and applications across multiple cloud offerings and on-premises environments, thus further enhancing the platform’s reliability.

