With rising DRAM costs, memory stranding is becoming an increasingly expensive problem in today’s data centers. One promising solution is the recent interest in far memory systems which pool the memory capacity across the servers over a network and allow more flexible memory allocations from the pool capacity. Despite providing a uniform memory abstraction to applications, these systems still work with a two-tiered (faster local and slower remote) memory underneath, and have to efficiently manage applications’ data between these two tiers to avoid significant application slowdown.
Existing far memory systems broadly fall into two categories. On one hand, paging-based systems use hardware guards at the granularity of pages to intercept remote accesses, thus requiring no application changes, but incur significant faulting overhead. On the other hand, app-integrated systems use software guards on data objects and apply application-specific optimizations to avoid faulting overheads, but these systems require significant application redesign and/or suffer from overhead on local accesses.
In this article, we present a new approach to far memory called Eden. Our key insight is that applications generate most of their page faults at a small number of code locations, and those locations are easy to find programmatically. Based on this insight, Eden combines hardware guards with a small number of software guards in the form of programmer annotations (or hints), to achieve performance similar to app-integrated systems but with significantly less developer effort.
The cost of DRAM as a fraction of total cost of ownership (TCO) for hyperscalers has been growing at an alarming rate. A study at Meta estimates that the DRAM cost as a fraction of the cost of a server in their data centers rose from 15% in their oldest generation to 37% in their latest [1]. Similarly, Microsoft estimates the same fractional cost to soon reach up to 50% of the server cost in their data centers [2]. Given these trends, memory stranding—a common issue that results from imperfect scheduling of workloads with variable memory demands across servers with fixed memory capacity—becomes an increasingly expensive problem. These trends have prompted research efforts to address memory stranding by seamlessly exposing memory over the network from underutilized servers to oversubscribed servers, an idea referred to as far memory.
While the term is new, far memory is far from a new idea. Network-based memory pooling has been explored way back in the 90s, with systems like GMS [3] extending the operating system to transparently spill data to remote servers, but such systems clearly haven’t seen much adoption due to the large gap in latency between DRAM accesses (100s of nanoseconds) and network round trips (few milliseconds). There is, however, a renewed interest today as the networks move from a millisecond to a microsecond era. While DRAM latency has not improved substantially (10s of nanoseconds now), advancements in networking hardware and adoption of technologies like RoCE [4] are delivering ever-higher bandwidth and lower latency communication between the servers—only a couple of µs within the rack. The large reduction in the remote-to-local memory access gap suggests performance concerns might not be insurmountable this time around. While smaller however, the gap persists, and the application slowdown caused by memory accesses that go over the network still remains a key barrier to far memory adoption. Thus, minimizing remote accesses with careful memory placement between local and remote memory is critical. At the same time, making remote memory transparent to the application is also important to avoid any application changes, which is also necessary for wider adoption. Existing far memory systems work towards and tussle between these two often-opposing goals.
The most straightforward approach to support far memory is to repurpose the OS paging hardware/software mechanisms to guard against and handle the far memory accesses. Application memory pages not in active use can be offloaded by transparently unmapping the pages from the application’s address space (page tables). Future accesses to this memory, guarded by the processor hardware that includes the translation look-aside buffer (TLB) and the memory management unit (MMU), trigger page faults that are handled by the OS paging mechanisms, which then fetch the pages from swap and map them into page tables. One recent system that uses this approach is Fastswap [5].
The advantage of this page-based approach is that it requires no application modification as it extends the same virtual memory abstraction that has been traditionally used to hide the physical memory to include remote memory. The approach also introduces no new overheads when all the data (pages) are in local memory, unlike app-integrated systems as we discuss below. However, the complete transparency of the approach, which has historically been its strength, also prevents the OS kernel from obtaining the fine-grained memory access information needed to implement workload-informed policies that could significantly improve performance.
To understand these challenges, let’s use a synthetic example of a Web server frontend (borrowed from AIFM [6]) that lets users store their data (e.g., photos) and request them as necessary. The application stores user metadata in a hash table (128-B entries) which indexes into a large array where the images (8 KB, 2 typical OS pages) are stored. Compared to the array, the hash table is accessed far more intensely (32x under their sample workload) but also at much finer granularity (64x) for each request on average (outlined in Figure 1). To understand how this application behaves with OS-based far memory, we run it with Fastswap, a recent OS extension to support far memory [5]. Note that we can run the application as is without any changes. We then measure the request throughput under a Zipf (1.0) distribution as we limit the size of local memory available to the application; Figure 1 (right) shows the performance normalized to fully local configuration. We see that the performance with OS-based far memory (Kernel) degrades almost linearly despite the fact that by far most accesses go to the much smaller hash table that fits in a fifth of the total memory usage. Digging further, we observed that, in absence of fine-grained access information, the OS lets the larger blob array pages kick out the much denser and more performance-critical hash-table pages to remote memory.
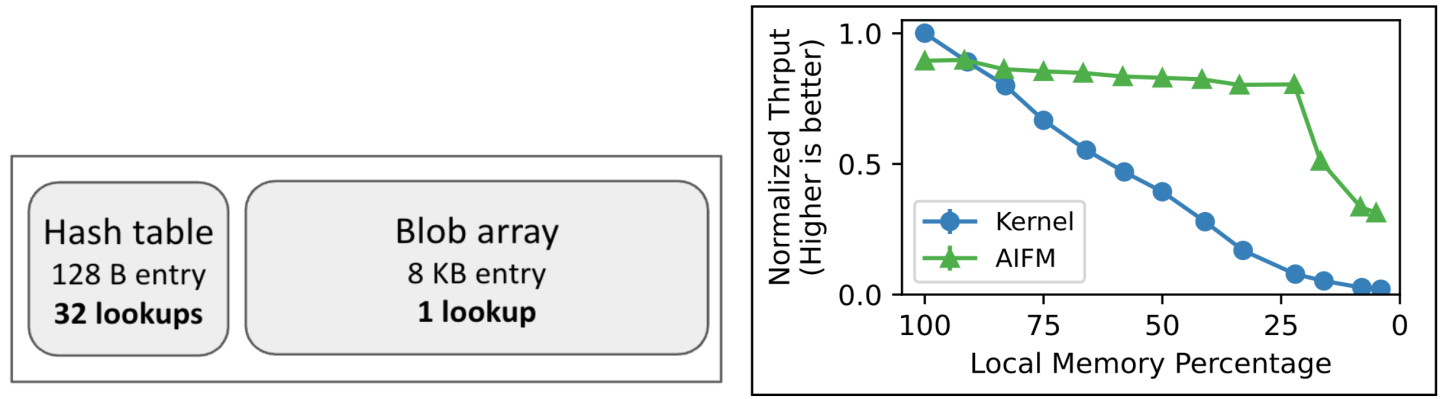
App-integrated systems like AIFM move far-memory management completely into the application and manage memory at object granularity, in a fashion similar to object-based language runtimes like the Java virtual machine. By operating at object granularity, they enable the runtime to track/isolate memory accesses to various data structures in the application and let the programmer or compiler provide insight into the expected access behavior among different data structure groups (e.g., prioritization between data structures) or within them (e.g., data structure-specific prefetching schemes). For our example application, the AIFM authors modified it to allocate memory using AIFM’s custom object-based memory allocator where the hash table and blob array objects are marked with different data-structure identifiers (DSIDs). All object accesses must be modified to use AIFM’s memory-access interface based on C++ smart pointers, to be handled by the AIFM runtime. The interface then optionally lets the programmer flag certain accesses as non-temporal, i.e., free to evict them after use, which the authors use to set the less-critical blob-array accesses as non-temporal, dramatically improving the performance (green line in Figure 1). This example demonstrates the power of even simple workload awareness in optimizing data placement, and thereby improving application performance, in a far memory setting.
However, there are downsides to the object-based approach. Without the TLB/MMU support that page-based systems avail, this design requires guarding all object accesses in software, with, e.g., indirect pointers (AIFM uses C++ smart pointers) upon which the runtime can interpose to check that the data is in local memory, and if not, read it from far memory. This pervasive indirection can add significant additional overhead; the astute reader may have noticed this overhead at 100% local memory in Figure 1. Furthermore, for correctness, these guards must be added at every potential far memory access which can result in significant code modifications. For example, porting a C++ DataFrame library [7] (which is similar to Python Pandas) to use AIFM required modifying 1100 (7.7%) of the nearly 15500 total lines of code.
There have been efforts to address both of these limitations. To avoid invoking guards on every access, AIFM employs programmer-assisted dereference scopes—small blocks in the program code—wherein the object is marked unevictable and guards are avoided using native pointers. Such optimizations, while helpful, are not always applicable (e.g., streaming workloads where objects experience a single access) and may even add to the programmer burden. For example, the DataFrame library above sees up to 30% slowdown with AIFM even after these guard optimizations.
In an effort to reduce the burden on programmers, AIFM provides far-memory-aware versions of standard data structures (e.g., C++ STL library), but many sophisticated applications eschew such generic libraries in favor of more efficient alternatives. More recently, systems such as TrackFM [8] and Mira [9] use compiler techniques to programmatically insert software guards in arbitrary code. While effective at reducing programmer burden, neither can eliminate the overhead of guards. They are also burdened by compiler limitations like the restricted scope of static analysis techniques such as when the compiler cannot statically resolve branching, function calls, or shared accesses from multiple threads. For correctness, they require source code for external library dependencies of an application which may not always be available. In addition, they also result in larger binaries (2.4× with TrackFM) and longer compilation times (6×). While these efforts represent a promising direction, we ask a fundamentally different question with Eden: Do we need to resort to an object-based approach and necessitate interposing/guarding every potential far memory access in the program to unlock access patterns?
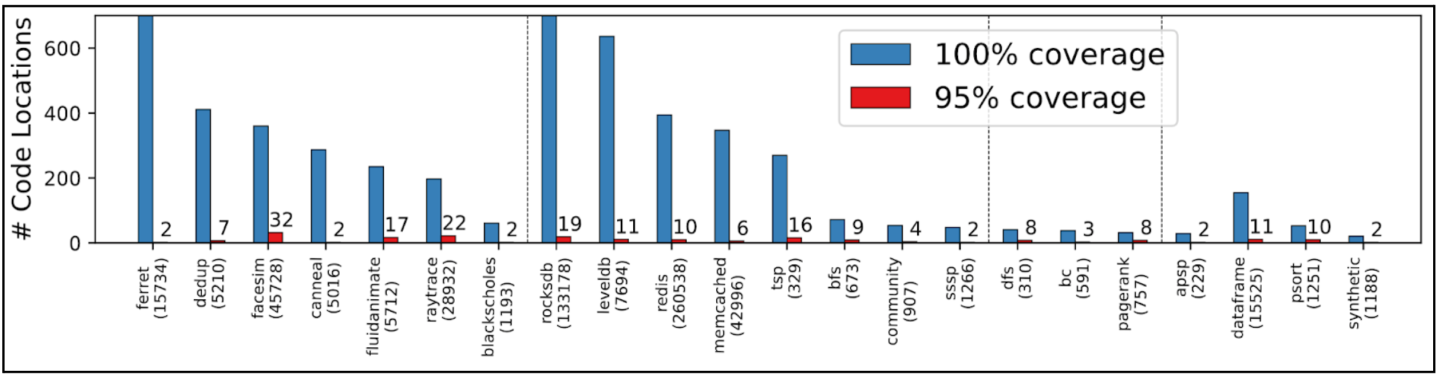
Not surprisingly, our answer is that it is not necessary to guard every memory access in a program, even those that operate on data structures that may be stored in far memory. To understand why, let’s look at the far memory accesses for the DataFrame library when deployed on a page-based system like Fastswap. We run it with a standard analytics benchmark and capture all the page-faulting (i.e., far-memory accessing) code locations as we limit the local memory available to just 10% of its maximum memory footprint (RSS), using our custom fault tracing tool (https://github.com/eden-farmem/fltrace). Even at this extreme configuration, we observe that of the 15,000 total lines of code, only 155 of them ever access pages that are not currently local. Moreover, if we order them by access frequency, the top-11 code locations cover 95% of all the far memory accesses! In other words, in theory we should be able to characterize the vast majority of far memory accesses and convey it to the runtime by focusing on just these 11 code locations. We did a similar profiling again at 10% local memory for a range of workloads from various suites like PARSEC, key-value stores from LK_PROFILE and graph algorithms from CRONO. Figure 2 shows the results indicating that this is a general trend: In most cases, a small number of code locations cover 95% of faults—12 locations at the median and fewer than 32 for all applications. A more in-depth study from our earlier work [10] also shows that the set of locations do not change much as we change the local memory ratio. Manual analysis reveals the reason is straightforward: a few “hot” code paths are responsible for most page faults in these applications. At even 10% of the maximum resident set size, local memory is sufficiently large that each page brought in on a code path tends to remain available for later page accesses in that path. As a result, only the initial reference on a given path is likely to cause a fault.
Of course, there are still occasional non-local references made by other lines of code. Yet, Amdahl's Law suggests that even if servicing these rare, unexpected page faults is relatively expensive, they are unlikely to scupper overall performance. Hence, the relevant question becomes: What kind of far-memory interface/system design could let us exploit these few code locations to implement performance optimizations while preserving correctness across the remaining, untouched memory accesses? Our answer is Eden.
Eden’s key goal is to detect and service actual remote memory accesses with software guards in the common case while avoiding the need to insert software guards in the vast majority of code locations where memory accesses are likely to be local. Eden achieves this goal by defaulting to traditional, MMU-enforced page faults for unexpected remote accesses, but allowing the developer to add a small number of hints to their program at locations where remote accesses are most likely to occur. These hints or software guards allow Eden’s runtime to efficiently check in user space whether the needed page is present and initiate its fetch if not. More importantly, these hints provide an opportunity for developers to convey additional application-specific information about their memory-access patterns to customize prefetch and reclamation policies. This parsimonious use of software guards balances their expressive power against their runtime overhead. Moreover, we provide a tracing tool that automatically identifies lines of code that would benefit from hints to simplify the developer’s task.
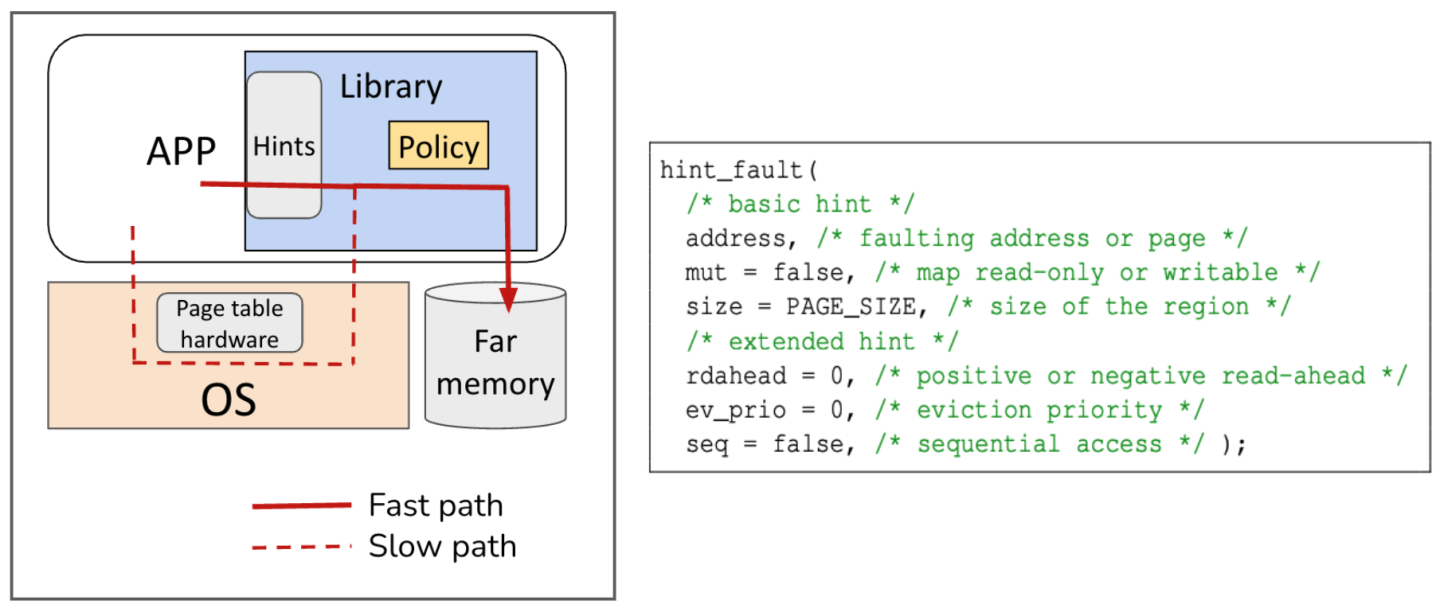
Figure 3 (left) illustrates Eden’s design at a high level. To support lightweight hints/software guards and retain flexibility, Eden performs memory management from a user-space library/runtime within the application, similar to AIFM. To retain hardware guards for most accesses however, Eden manages memory using OS pages. When we combine software and hardware guards, remote data fetches may be initiated either through our user library (software guards) in the common case or rarely via MMU-triggered page faults (hardware guards). To ensure consistent operation for all far memory accesses, Eden routes page faults triggered by hardware guards to its user-level library through Linux Userfaultfd. In either case, Eden’s runtime fetches the page from far memory via RDMA and uses the UFFDIO_COPY ioctl to allocate a physical page, copy the fetched data in, and map it in the process’ page tables. Under memory pressure, Eden first picks the pages to evict to remote memory under a custom policy guided by the programmer hints, protects them with UFFDIO_WRITEPROTECT so that they cannot be modified during eviction and finally unmaps the pages from OS page tables using madvise (MADV_DONTNEED) syscall. One of the key contributions of Eden is to provide batched variants for these Linux syscalls to amortize their overhead for each page [11]. Finally, Eden provides a hint interface shown in the Figure 3 (right) with basic and extended hints. While basic hints enable the remote accesses to take the faster software path, these hints can be arbitrarily extended to provide workload-specific information such as read-ahead and eviction priority. Our code is publicly available at https://github.com/eden-farmem/eden.
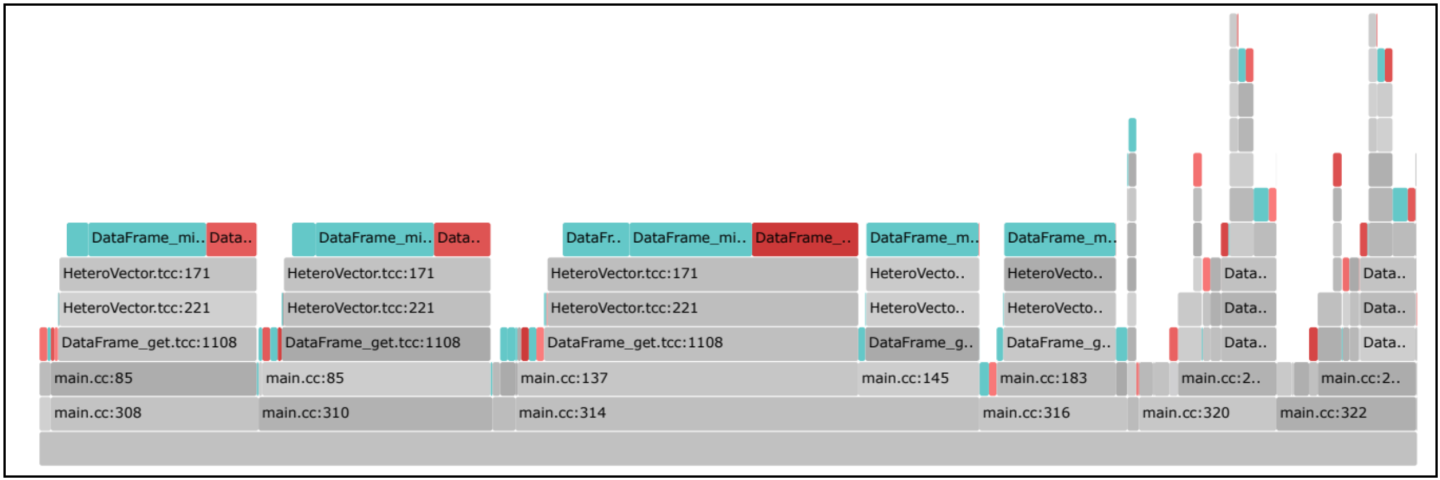
A win for Eden means two things: 1) It is easy to add hints and run an application with Eden and 2) such hints can unlock performance benefits comparable to fully app-integrated systems like AIFM. Eden meets both these criteria for the two applications we looked at in this article. To port each application to Eden, we first run the unmodified version with our tracing tool to reveal frequently faulting code locations. Figure 4 shows the example output for DataFrame in the flame graph format. The tool runs transparently with LD_PRELOAD for the entire duration of the application. In practice, we were able to find most faulting locations in a few seconds to minutes using small, representative inputs. We then add hints at the top locations, along with the information about the access pattern of that particular data structure and link it with Eden library.
For the example Web application, we find that 14 locations ever trigger a far memory access and most faults (99%) come out of just two code locations. Not surprisingly, one location corresponds to the hash table lookup and the other to a blob array access, requiring a hint for each. Recall that our original goal was to differentiate between these two data structures and convey different priorities at each annotation, which we do by setting a higher eviction priority for the hash table access, achieving a similar result as AIFM’s non-temporal feature but without switching to a custom STL library. Adding Eden’s performance to the original Figure 1 in Figure 5 below, we can see that Eden recoups much of the performance lost by OS-based far memory, and even out-performs AIFM when most memory is local due to its vastly decreased software-guard overhead. When local memory becomes extremely constrained, both Eden and AIFM are forced to evict hash-table entries, which leads to I/O amplification in the case of Eden. Specifically, AIFM is able to reference far memory on a per-object (4-B) basis, while Eden must pull in—and evict—entire (4-KB) pages at a time, resulting in less efficient network bandwidth and local memory utilization.

We repeat the same with the DataFrame library as well. Figure 6 (right) shows the normalized run time of an analytics benchmark using the library with various systems. In this case, AIFM performs well due to prefetching as most accesses scan over column vectors. The OS-based prefetcher cannot effectively prefetch as it relies on guessing the trend and interleaved access streams from various concurrent scans throw off its trend detection for even simple sequential scans; AIFM can cleanly separate these streams due to data-structure level access tracking. With Eden, we use the extended hint API to provide specific read-ahead parameters at each hinted location (an example shown in Figure 6), bringing the performance in line with AIFM. Eden achieves this performance with just 23 lines of code modifications, whereas AIFM required almost 1100 to switch to its custom object API, nearly a 50x reduction!

In this article, we presented Eden, a new point in the design space of far memory systems that combines software and hardware guards to intercept accesses to remote memory. Eden uses software guards at the few code locations where most of the remote accesses tend to occur, while relying on hardware guards elsewhere in the application. This approach unlocks workload-informed memory management and provides good performance—better than paging-based approaches (pure hardware guards) and comparable to prior app-integrated systems (pure software guards) without their issues. It does not, however, tackle a few remaining limitations with page-based accesses like the less-efficient local memory and network bandwidth utilization for applications that work with objects much smaller than a typical OS page; we leave these for future work.
While this article focuses on network-based approaches to far memory, it is worth acknowledging Compute Express Link (CXL.mem) as an emerging PCI-based technology for memory pooling. CXL.mem is not yet widely deployed in production environments, but takes a different design point that further cuts down the latency and enables more efficient out-of-order execution when accessing remote memory. However, it introduces its own challenges including switch infrastructure overhead and additional levels of indirection, and it remains dependent on OS-level policies for hot page detection, reclamation, and prefetching. These limitations suggest that insights from Eden regarding application-specific memory access patterns will remain valuable across both network-based and PCI-based memory pooling paradigms as hardware solutions continue to evolve.






