Programmers make mistakes, and these mistakes leave computer software vulnerable to exploitation. Even today, programmers often rely on unsafe languages such as C and C++ for their high performance and large control over memory management. Unfortunately, secure programming is difficult to get right, and when the programmer manages memory improperly, it often results in memory safety vulnerabilities. The consequences of memory errors can be severe, as for example demonstrated by the notorious Heartbleed [3] vulnerability, which left a large number of web servers open to attacks. Even after decades of combating such memory errors, Microsoft and Google report that about 70% of their serious security bugs continue to be memory safety issues [1, 2].
Thankfully, we can detect these memory errors through software testing tools, but they often come at the cost of significantly slowing down programs at runtime. We have developed FloatZone to overcome these performance issues by leveraging an underutilized unit of modern CPUs. In this article, we explain how FloatZone works and show that it can detect memory errors faster than existing solutions.
Driven by the many security incidents involving memory errors in system software, sanitization for memory safety has become a standard technique for bug discovery in software testing. Sanitizers are powerful tools usually aimed at discovering two main categories of bugs: spatial and temporal memory violations.
- Temporal safety: all memory accesses to an object must happen during its lifetime. For example, use-after-free and double-free bugs are violations of temporal safety.
- Spatial safety: all memory accesses must occur within bounds of the referenced object. For example, heap and stack buffer overflows are violations of spatial safety.
Unfortunately, identifying which memory accesses are in fact memory safety violations is not easy. Consider the following small example:
int *ptr = …;
*ptr = 123;malloc(), the resulting memory layout with redzones looks like this:

In order to detect erroneous memory accesses, the sanitizer must distinguish between accessing valid and invalid (redzone) memory. To achieve this, sanitizers, such as AddressSanitizer [4] (ASan), commonly accompany every memory access with a runtime check for validity. These checks have the following form:
While sanitizers are crucial for identifying and debugging potentially exploitable bugs, these memory error detection capabilities come with a steep cost. ASan slows down target programs by roughly 2x, and therefore typically does not see production deployment [8, 9], but the high overhead also negatively impacts the number of executions in an automated software testing campaign (e.g., fuzz testing). The main component of this slowdown originates from the pervasive checks for validity. In fact, a recent analysis attributes approximately 80% of ASan’s overhead to the checks [5].
When we put the checking logic under a microscope, we observe that the resulting operations can be expressed as a “lookup, compare, and branch” paradigm.
Since the sanitizer must apply these checks to every potentially unsafe load and store operation, speed is of the essence. For this reason we have to carefully inspect the cost of each component to understand the performance of such checks. Depending on how the sanitizer maintains its redzone metadata, the lookup(ptr) operation can be as little as a single load, but it can also involve more complex logic like pointer arithmetic followed by a load (for lookup tables). On top of this, the subsequent compare-and-branch steps induce a branch-heavy control flow, forcing the CPU to waste precious clock cycles on jumping around instead of performing the original workload.
With all these challenges in mind, we ask the question: can we accelerate these checks to achieve fast memory error detection?
In our research, we find that a floating point addition can be made to generate an exception if it processes redzone data. We achieve this by configuring a floating point addition to result in an exception if and only if one of the operands is equal to our redzone poison value. By instrumenting load and store operations with the addition, we ensure that redzone accesses raise an alarm, as visualized in Figure 2:
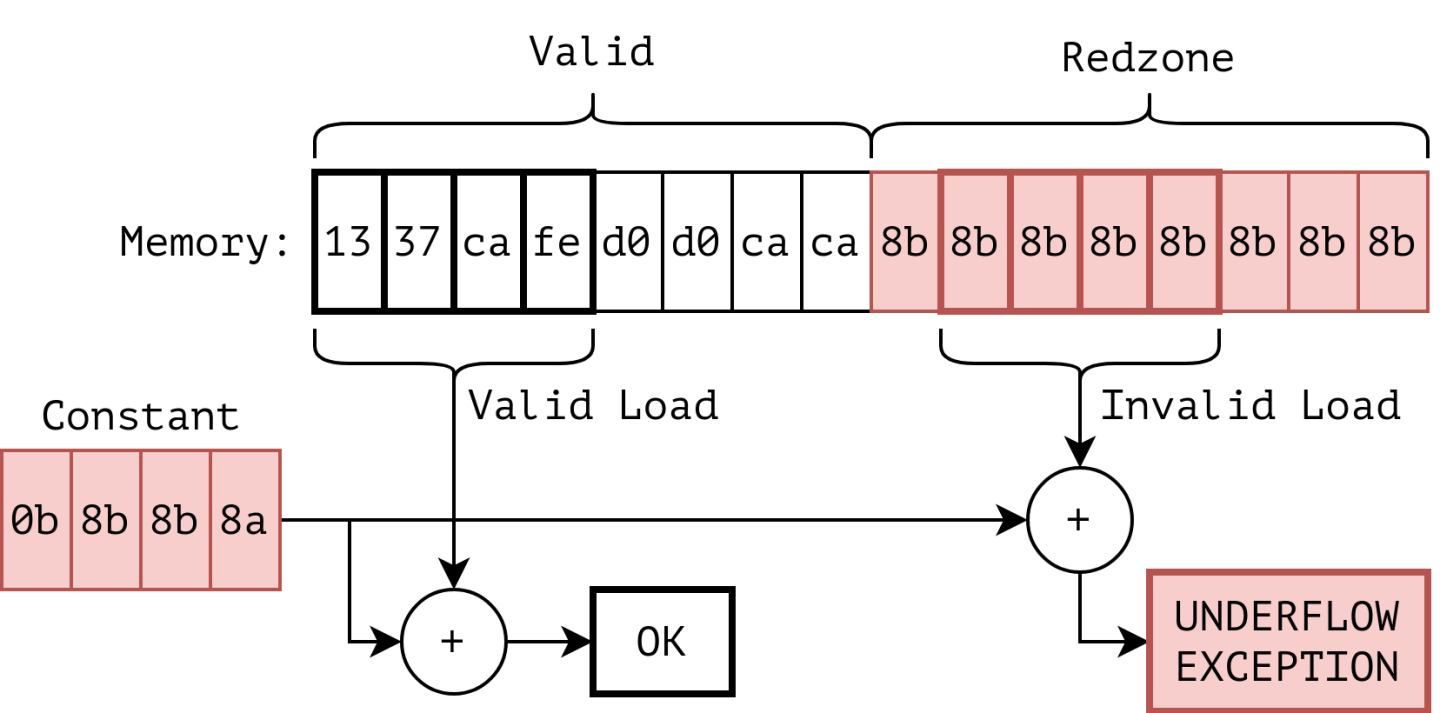
By expressing checks using floating point exceptions, we can gain great benefits:
- The cumbersome compare and branch steps are replaced by the existing CPU hardware logic that implicitly detects exceptions.
- Keeping the control flow of the program as-is (no additional branching) promotes efficient use of the CPU frontend and branch prediction.
- The addition is performed on an execution unit that is underutilized in most programs (the FPU), allowing for high instruction-level parallelism.
We found the specific operands of the floating point addition by considering various constraints. First, we need to avoid collisions with other numbers as much as possible to avoid false positives. In essence, we look for a fixed value x such that we can find only one (or few) y value(s) where x + y generates an exception. Second, we require that y follows a byte-wise repetitive pattern (e.g., 0x4a4a4a4a) for redzone alignment reasons.
With all these constraints in mind, by searching the floating point number space in a brute-force manner, we discovered a suitable configuration. Specifically, with x = 5.375081 · 10−32 (x=0x0b8b8b8a), x + y causes an underflow exception only with y = −5.3750813 · 10−32 or y = −5.37508 · 10−32 (y=0x8b8b8b8b or y=0x8b8b8b89). These exceptions occur because the result of the addition is such a small number that it cannot be correctly represented in a single-precision (32-bit) floating point number. Also, note that y=0x8b8b8b8b is a byte-wise repetitive pattern.
The specific combination of numbers that we discovered allows us to express the comparison in Listing 3 by performing float(y) + float(0x0b8b8b8a). Note that the exception is only raised if y is equal to one of the two identified values.
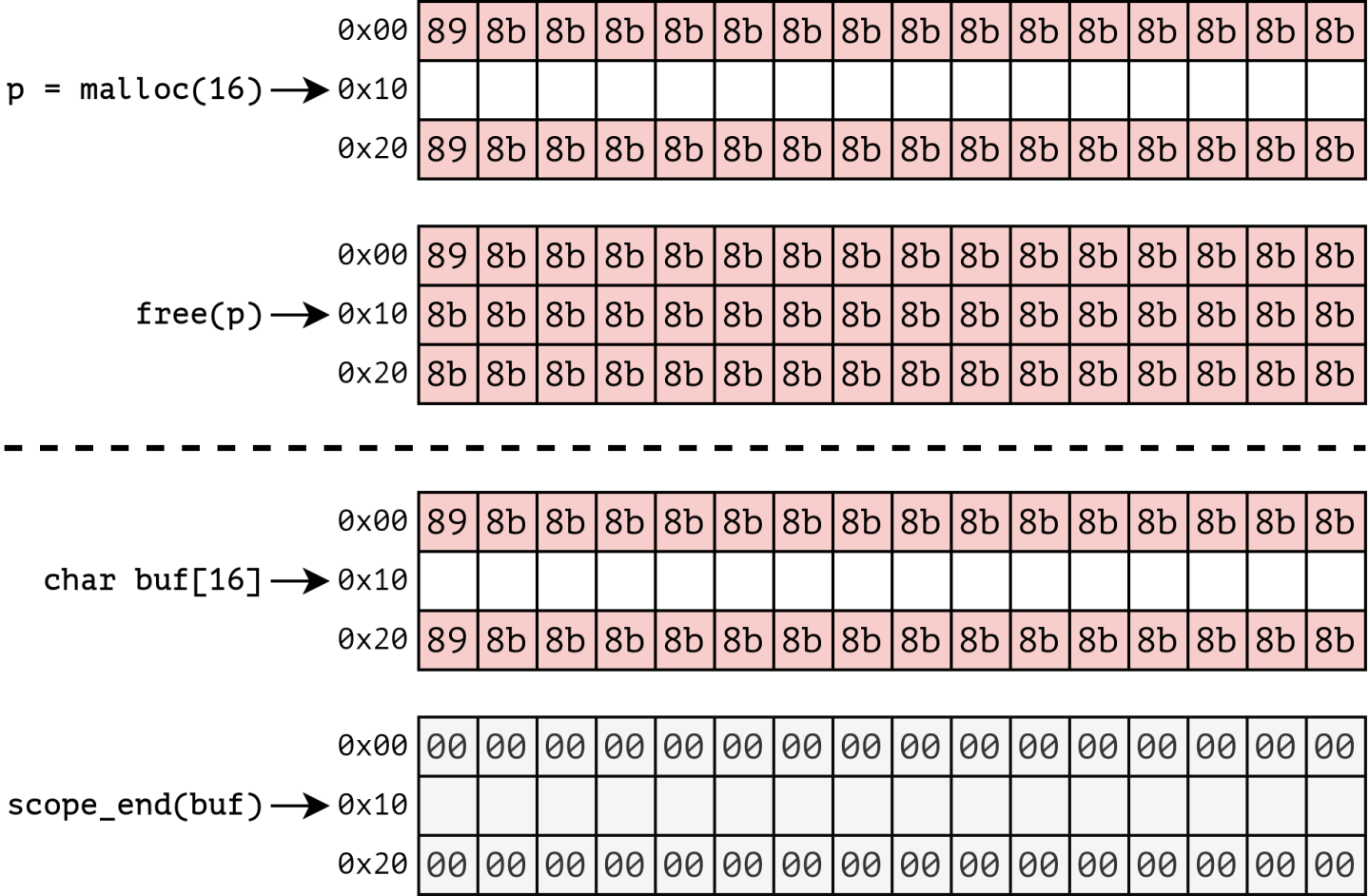
Now that we have an efficient means to evaluate if a four-byte memory location holds 0x8b8b8b8b or 0x8b8b8b89, we briefly visualize how we built FloatZone: a sanitizer for spatial and temporal memory issues. See Figure 3 for an overview of how FloatZone inserts redzones for spatial and temporal memory error detection on the stack and the heap. We place our four-byte float constant (0x8b8b8b8b) around each memory object, repeating it as necessary (for example to create 16-byte redzones). We employ a repetitive poison pattern (0x8b8b8b8b), allowing us to read four bytes from the starting point of any memory access without further requirements for alignment. This concept is visualized in Figure 2 (above), where it is clear that any four-byte access within the redzone results in the same poison pattern being read. When discovering our repetitive poison value, we noticed that there is one additional colliding value: 0x8b8b8b89. Since the 0x89 byte is stored as the first byte in little endian representation, we can use it as a start marker for our redzone (see Figure 3), which ensures that we can separate objects ending in 0x8b from the start of the redzone.
Our performance evaluation shows that floating point additions are significantly faster than compare-and-branch instructions, and newer CPU architectures widen the gap even further. We created two compile-time instrumentation passes that either insert a floating point addition or a compare and (non-taken) branch on every memory access, and apply this to the SPEC CPU2006 benchmarking suite. Figure 4 displays the runtime overhead results of this experiment, across various CPU generations.
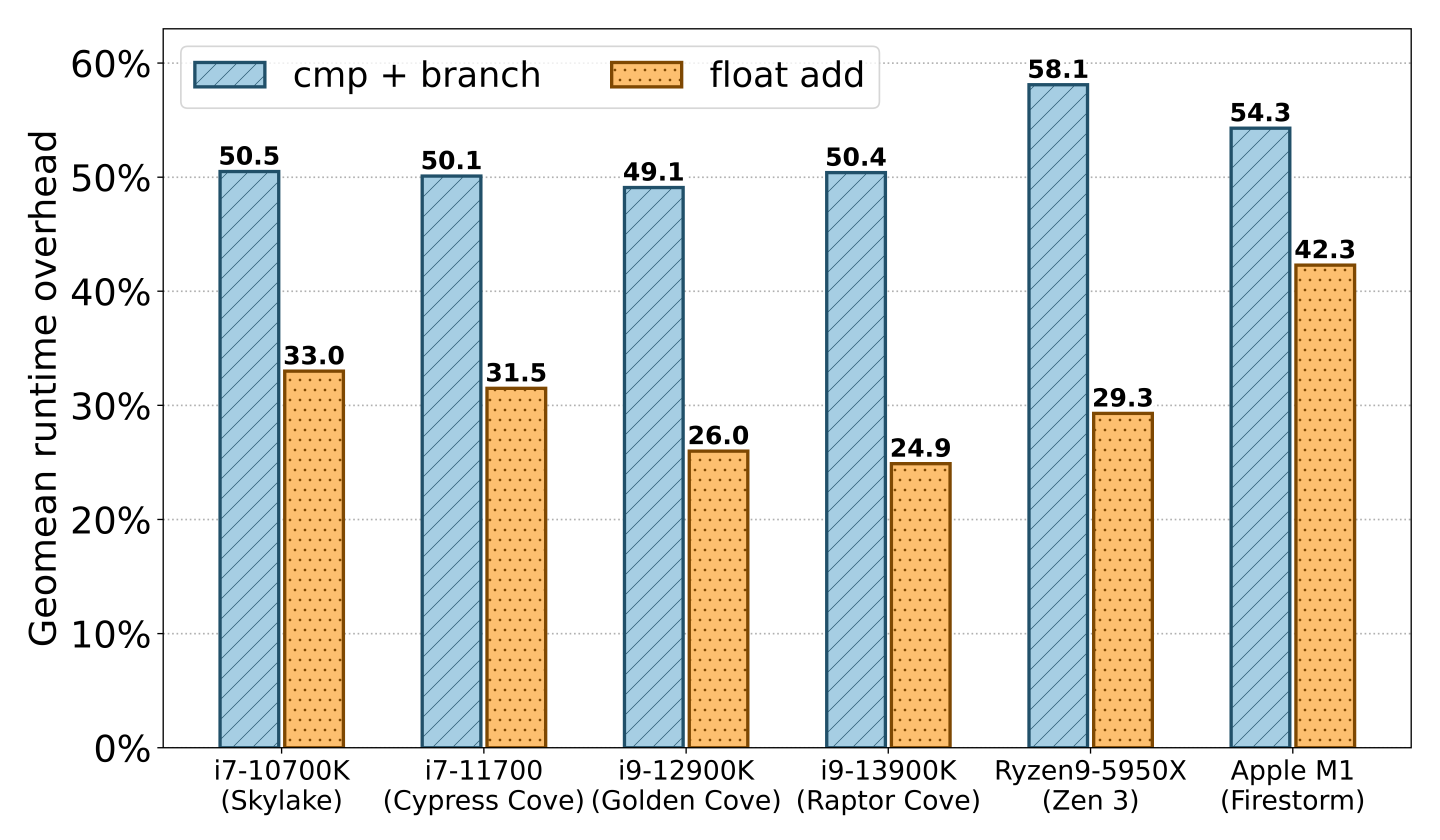
For the compare-and-branch instrumentation, we observe that across all Intel microarchitectures the relative runtime overhead remains nearly identical at a geomean of 50%. In the most recent generation Intel CPU (i9-13900K), the geomean runtime overhead of inserting a float add is 24.9%, which is half the relative cost of a cmp+branch, and also 8 percentage points lower than the float add pass on the less recent i7-10700K. These results suggest that the FPU has become significantly faster in recent Intel generations. This hypothesis is supported by the fact that two additional FADD (Fast Add) units were added to the pipeline on the Golden Cove microarchitecture [6]. We additionally verify that the FP addition benefits are not Intel-specific by performing the same evaluation on an AMD Ryzen 9 5950X with the Zen 3 microarchitecture and an Apple M1 (Firestorm).
Next, we evaluate the runtime overhead of FloatZone using floating point exceptions to sanitize memory errors. Figure 5 displays the runtime overhead of FloatZone on each individual SPEC CPU2006 binary. Overall, FloatZone results in a geomean runtime overhead of 36.4%.
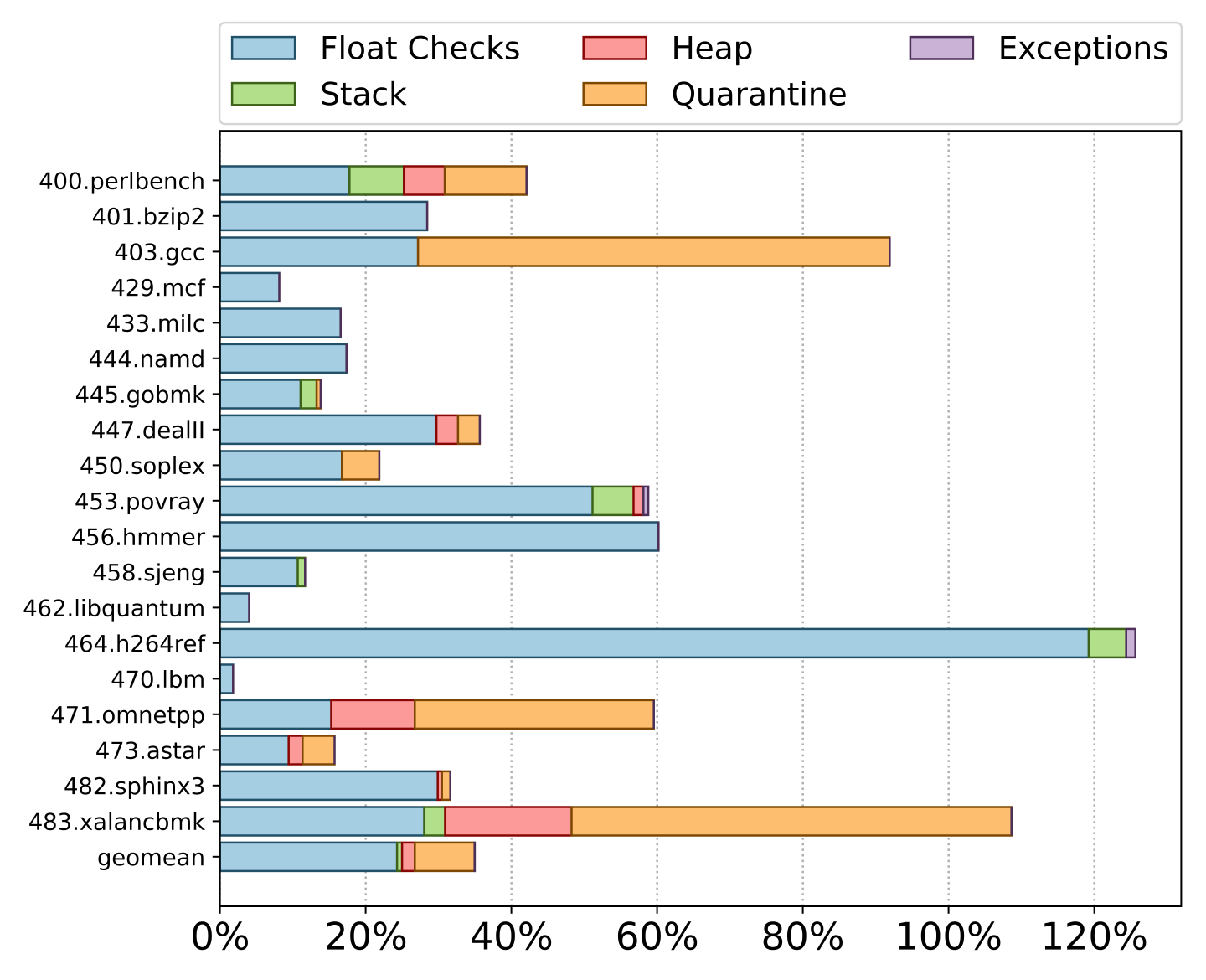
Most of the overhead originates from the floating point checks (25%, as also seen above in Figure 4). After the float checks, the heap quarantine is the second largest factor in the overhead buildup. While quarantines are orthogonal to our design, they do introduce overhead to ensure heap memory is not immediately re-used to guarantee temporal memory error detection. The remaining overhead originates from managing redzones on the heap and the stack, combined with the small costs of enabling floating point exceptions.
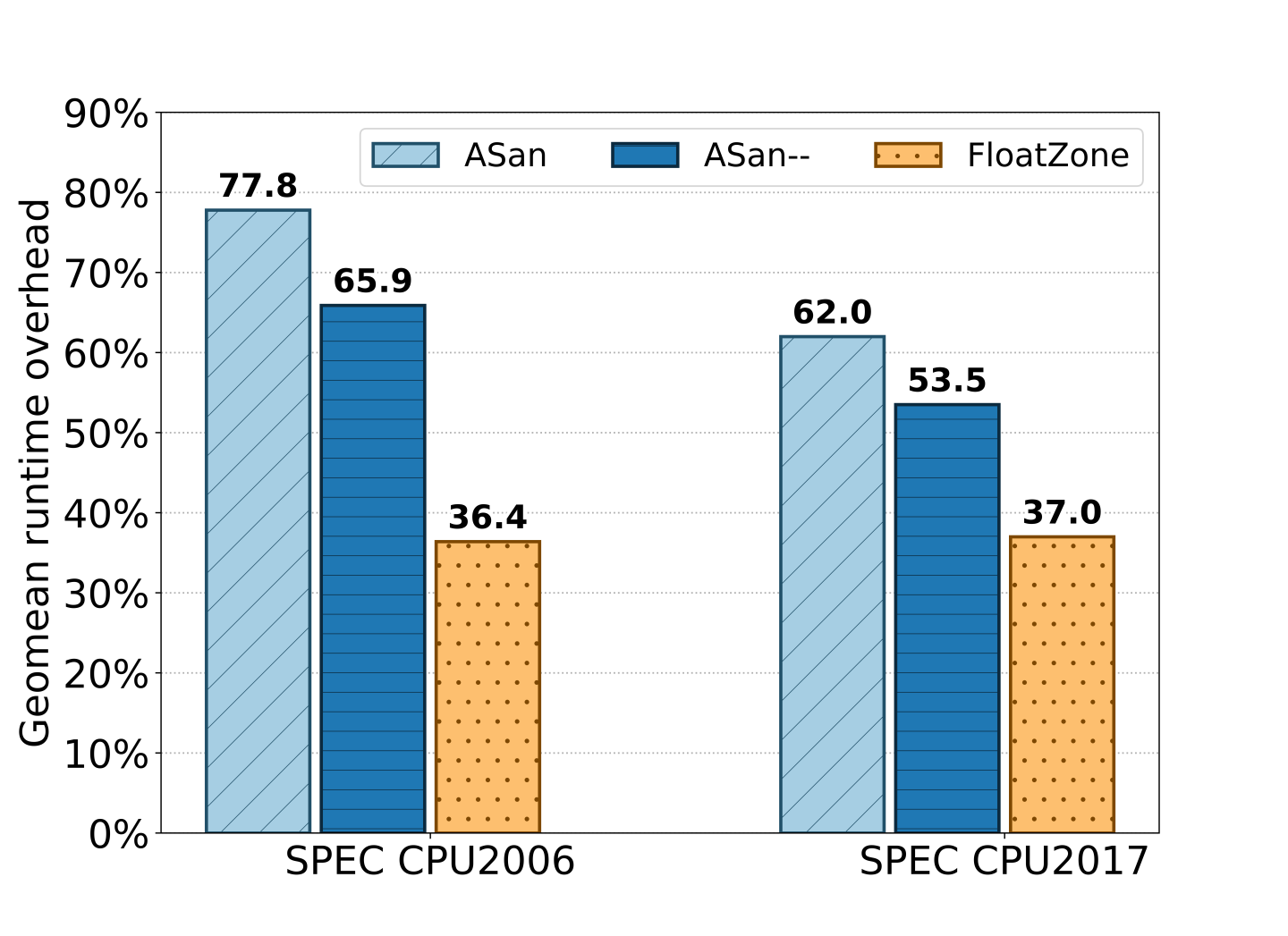
To put the overhead of FloatZone into better perspective, we compare the overhead to a state-of-the-art sanitizer: ASan (and ASan--, an optimized version of ASan), using both the SPEC CPU2006 and CPU2017 benchmarking suites. In comparison, ASan and ASan-- report overheads that are significantly higher (see Figure 6): 77.8% and 65.9% on SPEC CPU2006, respectively. Here, FloatZone is more than twice as fast as ASan. On the more recent SPEC CPU2017 benchmarking suite, FloatZone shows a similar performance with a geomean runtime overhead of 37%, which is again significantly faster than ASan(--).
Sanitizers for memory safety have become a standard in software testing, and despite recent optimizations, state-of-the-art bug detection tools still incur high runtime overhead. We improved performance by introducing a faster check for validity on commodity hardware. We showed that we can use floating point arithmetic to express the common compare-and-branch sanitizer paradigm. We used this primitive to build a memory sanitizer called FloatZone, that relies on carefully crafted floating point underflow exceptions to identify memory violations. We showed these checks using floating point additions are indeed notably faster than comparison instructions. Moreover, we showed that our resulting sanitizer significantly outperforms the state-of-the-art solutions.
For more information on FloatZone, we refer to our publication: ‘FloatZone: Accelerating Memory Error Detection using the Floating Point Unit’, in USENIX Security 2023 [7].




