ThousandEyes’ infrastructure has humble origins. Around the year 2010, our founders scavenged the first servers out of the recycling bins of bigger companies in Silicon Valley, and quickly set them to run in a garage in Mountain View. Against all odds, ThousandEyes grew: bigger customers, bigger contracts, and, of course, bigger reliability concerns. Having a proper infrastructure in place was in order, so the scavenged servers were repurposed and racked in a data center. A few years later, pricing and location compelled a migration to another data center close to the company's headquarters in downtown San Francisco.
Around 2015, ThousandEyes’s main infrastructure consisted of four racks with a bunch of servers, some of them running Xen on Debian, and our main application, a Software-as-a-Service (SaaS) offering, running on three Virtual Machines (VMs) behind a physical load balancer distributed between three of those racks–a standard setup at that time.
The company was growing faster than we could scale our infrastructure, so we had to design a solution for hyper-scaling. That's when Kubernetes came into the picture. Today, it sounds like the obvious solution, but when we started experimenting with it, we didn't know if it would live up to the hype. Our platform was made of, for the most part, monolithic applications. Our software footprint was small enough, and containerizing everything was a daunting but doable effort. This was our first big migration.
Our first iteration of the cluster was running the now defunct CoreOS, with Kubernetes version 1.1.2; we named it k8s1. We hosted absolutely everything in our data center: Continuous Integration (CI) pipeline, Docker registry, etcd cluster, Kubernetes control plane. The original four racks expanded to a cage with ten racks. Each Kubernetes worker was a bare-metal server that had to be racked by our team and bootstrapped using Shoelaces, an in-house server bootstrapping automation tool we open-sourced years ago.
CoreOS was new to us; the rest of our fleet was running Ubuntu 14.04 at that time, and servers were configured using Puppet 3. Being new to the Kubernetes world and running containerized applications, we took the bait and chose that OS. It made perfect sense in theory: a container-optimized Operating System (OS) for a container orchestration system such as Kubernetes. In practice, it was not the right fit for us, as we did not find it flexible enough. Most components were configured at boot time with a configuration file known as cloud-init, which meant we were not able to use our existing Puppet code base. Additionally, running custom processes and kernel modules was not straightforward; for example, we went through painful debugging sessions to integrate CoreOS with our network file system at that time, GlusterFS. We decided to migrate the cluster to Ubuntu, enabling us to use our then-modern Puppet 5 code base present in the rest of our infrastructure. It was early 2018, and we were running Kubernetes version 1.5.4.
This migration was simple but painful. The preparation phase involved writing a few Puppet modules and rounding a few sharp edges in Ubuntu to befriend it with our Kubernetes setup. During the implementation phase, we had to remove each CoreOS worker from the load balancer, shut it down, and use Shoelaces to bootstrap the server again with the new operating system. Slowly but surely, we pulled the tablecloth out from under the dishes, and our developers barely felt it.
We were a small team, busy and distracted by the myriad migrations and maintenance we were doing on the cluster itself, so we neglected to update k8s1 for several versions. We were stuck in 1.5 and upstream was already in 1.13—a non-negligible version lag.
Additionally, our Continuous Integration and Continuous Delivery (CI/CD) pipeline was not robust when it came to Kubernetes manifests. We used to have an internal tool, triggered by Jenkins, that would deploy manifests for us whenever there was a commit with a change in a given directory within each of our git repos. This approach made drift detection extremely challenging, as there was no way to visualize it. Additionally, the tool was not robust and it would fail to recognize some Kubernetes resources, or even crash when trying to parse a Git commit message–the kind of issues one typically deals with when building internal tools. In such situations, one encounters a build-versus-buy dilemma. However, in our case, being early adopters, we had no choice but to build as there were no strong solutions available in the market.
These were some of the circumstances that propelled us to spin up a new cluster instead of updating the existing one. We named it k8s2, and at bootstrap time, it was running version 1.15.3 in Ubuntu servers managed by Puppet 5.
We decided to pair the migration to this cluster with a radical change in how we deployed our manifests. We switched to a GitOps-based approach using ArgoCD, choosing it due to its strong community and ease of visualizing and remediating drift. With the help of upper management, we recruited the whole engineering department for this effort. Each team owned its Kubernetes manifests in their own Git repositories with their own Git practices, making it impractical for a single team to do all the work. With this new approach, we moved Kubernetes manifests into a separate repository. Our workloads would now have an extra repository with just Kubernetes manifests—all of them buildable with kustomize, a Kubernetes native configuration management tool.
Mid-migration from k8s1 to k8s2, we finally committed to something we knew had to happen sooner rather than later: migrating to a cloud provider.
Given the imminent expansion of our infrastructure, the need for another region in Europe, and a disaster recovery environment, using bare metal was no longer an option.
We needed to consider whether this decision to migrate to a cloud provider would change the course of our migration from k8s1 to k8s2 or if we would keep it the same way and only think about it once we finished. It was a trade-off we needed to consider. We decided to complete the migration to k8s2 given that we had the momentum and know-how in place, and at that time, many things were unknown to us regarding Amazon Web Services (AWS), our chosen provider.
The main requirement was to use AWS us-west-1 as our main region, given its close proximity to our data center in downtown San Francisco. There were, however, a couple limiting factors. Elastic Kubernetes Service (EKS), AWS' hosted Kubernetes product, was not available in that region, and the region only had two availability zones (AZs). Yet another trade-off to consider: do we wait for AWS to add EKS support? Or do we deploy our Puppet-managed cluster in Elastic Cloud Compute (EC2) instances?
We did not have a clear date from AWS and wanted a timeline we could control, so we decided to go via the difficult path and run Kubernetes directly on EC2s. We connected our data center and AWS us-west-1 with AWS Direct Connect (a product that connects private on-prem networks with Virtual Private Clouds) and added Kubernetes workers on AWS.
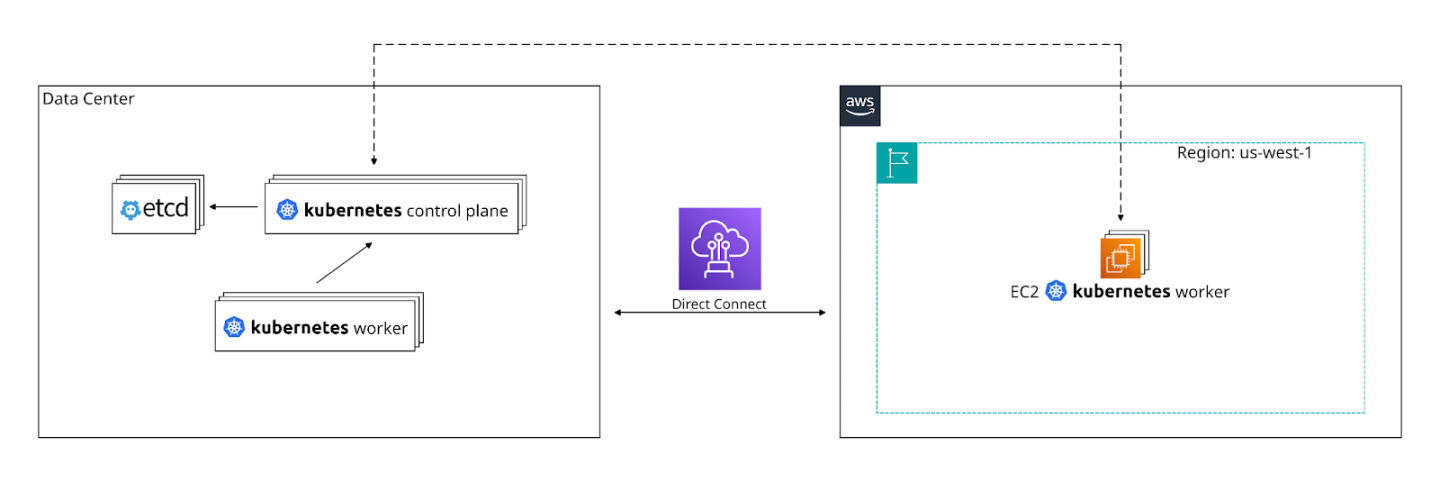
The AWS workers had taints so that our workloads wouldn't indiscriminately run in a different environment. “Taints” are node repellents that prevent pods from landing in that node. The counterpart to taints are “Tolerations”, which allow for pods to get scheduled despite the taints. Taints are applied to nodes, and tolerations to pods.
$ kubectl describe no k8s2-1-a
Name: k8s2-1-a
<...>
Taints: site=sfo2:NoSchedule
Our first EC2 workers connected to the data center Kubernetes control plane. We later added control plane nodes in AWS that maintained communication with the etcd cluster in the data center (etcd is a strongly-consistent distributed data store which the Kubernetes control plane uses to store critical state). The AWS-based Kubernetes workers connected to the new AWS control plane. Data center workers would still connect to the data center control plane. Under the hood, all the control plane nodes were connected to the etcd cluster, which was still running in the data center, but not for much longer.
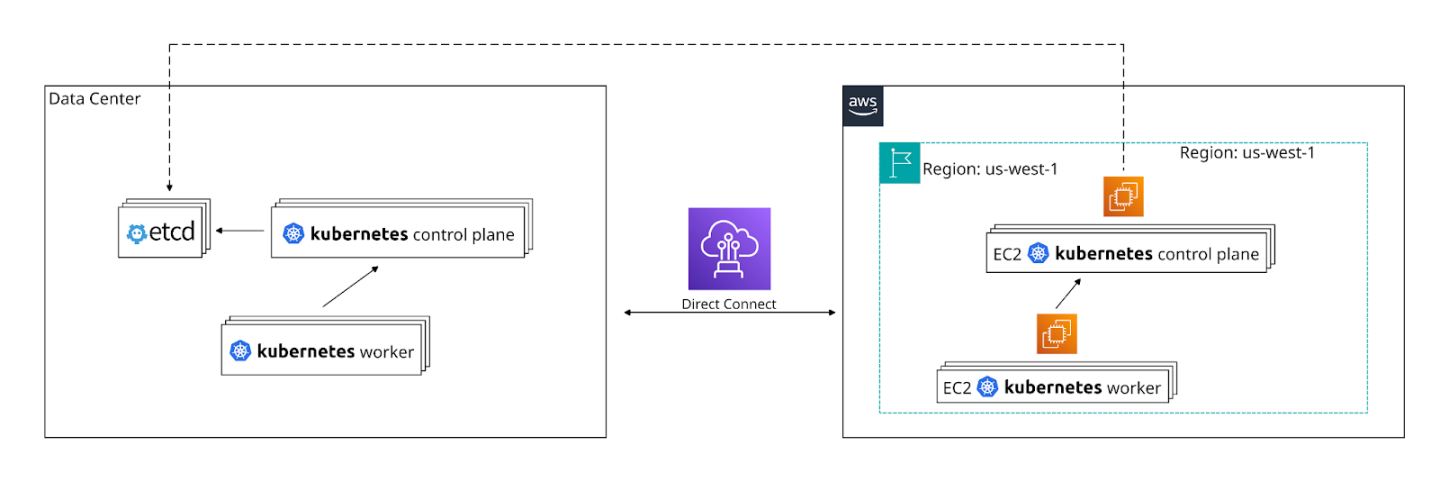
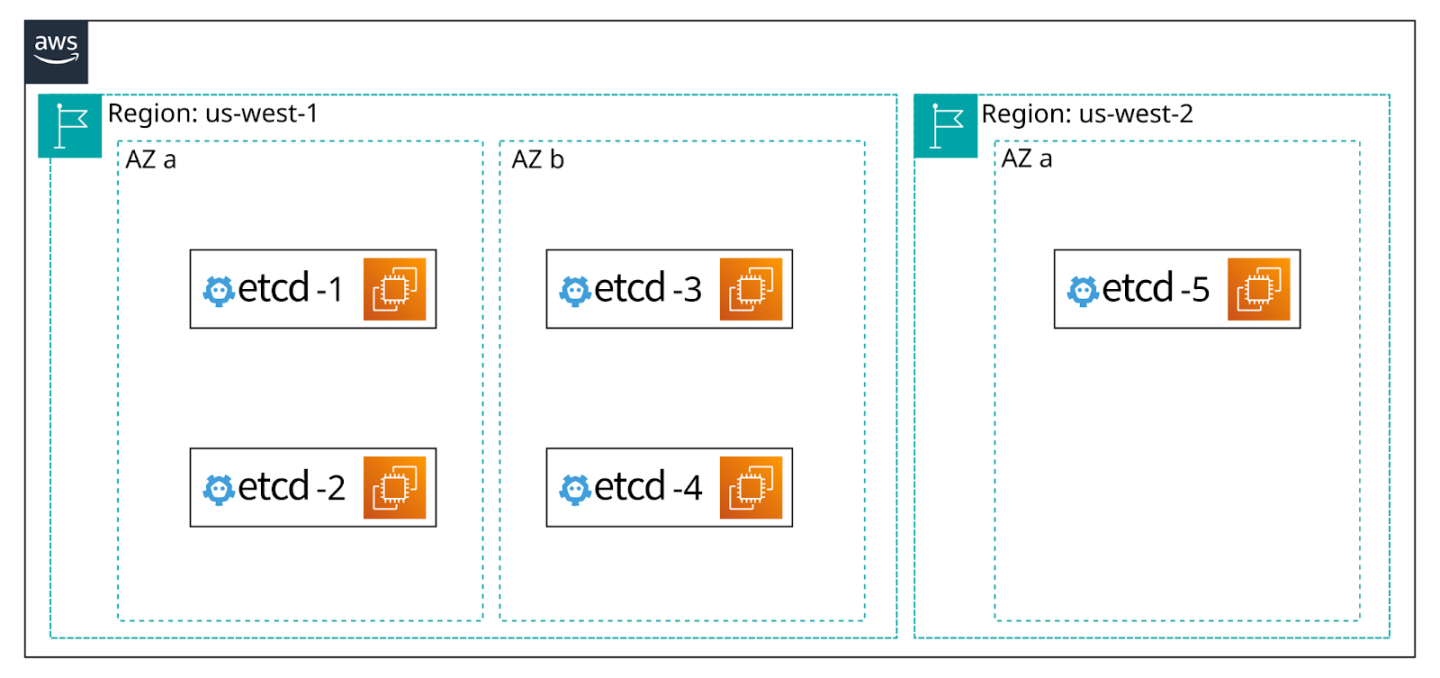
Migrating the etcd cluster was a different dance. We only had two AZs, but we needed three to ensure high availability, proper quorum, and avoid split-brain situations.
According to the etcd documentation [1], "an etcd cluster needs a majority of nodes, a quorum, to agree on updates to the cluster state. For a cluster with n members, quorum is (n/2)+1. For any odd-sized cluster, adding one node will always increase the number of nodes necessary for quorum. Although adding a node to an odd-sized cluster appears better since there are more machines, the fault tolerance is worse since exactly the same number of nodes may fail without losing quorum but there are more nodes that can fail. If the cluster is in a state where it can’t tolerate any more failures, adding a node before removing nodes is dangerous because if the new node fails to register with the cluster (e.g., the address is misconfigured), quorum will be permanently lost."
We ended up bootstrapping one node in us-west-2 and two nodes in each us-west-1 AZ, for a total of five. The Kubernetes control plane was configured to point only to the us-west-1 etcd nodes. The synchronization with the fifth node happened in the background. This was not an ideal solution, but it worked well enough for us without incurring noticeable latency. In the unlikely event of a us-west-1 AZ going down, latency would have slightly increased, especially under a constant stream of updates in the cluster. However, our cluster did not have that usage pattern, and ultimately, this increase would not have been significant enough to impact customers.
A notable difference in our AWS setup was the use of auto-scaling groups. We no longer had to rack and bootstrap new workers whenever we needed to scale. Instead, we decided to designate one ASG per team to segregate costs and noisy neighbors. We would control this behavior with node selectors and tolerations.
nodeSelector:
asg: webapps
tolerations:
- key: "asg"
operator: "Equal"
value: "webapps"
effect: "NoSchedule"
In retrospect, this might not have been the brightest idea. These requirements can easily metastasize, and we were now requiring team members to add node selectors and tolerations to all their workloads. A better approach would have been to compute these fields automatically based on, for example, the namespace to which they belong.
Workloads were migrated progressively at each team's discretion. Such was our luck that, when we were about 70% done, AWS announced EKS support in us-west-1. We thought about bootstrapping a new managed cluster and completing the migration there, given that it could save us from throwaway work. However, we considered this tradeoff and decided to finish the existing migration, given that there were many uncertainties in how we would implement EKS. Additionally, our staging environment had already been migrated. Starting anew would mean an environmental disparity, putting us in a precarious situation. We concluded that sometimes it makes sense to do throwaway work in the name of reliability.
ThousandEyes was experiencing growth, with a significant portion of our customer base located in Europe. Thus, the latency we had to our platform in us-west-1 was unacceptable, and expanding to a new region became paramount. We chose eu-central-1, a region with three AZs and full support for EKS.
We developed Terraform code to bootstrap an EKS cluster and mimic the per-team Autoscaling Groups (ASGs) we had in k8s2. Our vision was to spin up a ready-to-be-used cluster with a single pull request. In practice, we faced a few challenges that forced us to split the code into multiple layers: bootstrapping the cluster, installing core services via Terraform, and setting up load balancers.
In a relatively short amount of time, we had our new cluster, eks1, ready to be used. Our engineers were able to spin up their services, and shortly after, we started serving some of our customers in our EU region.
Shortly after our first EKS cluster was ready, we started receiving requests for more clusters: disaster recovery, team-specific, tool-specific, etc. We used each cluster to improve our bootstrapping process. Our Infrastructure as Code (IaC) modules allowed us to have cookie-cutter EKS clusters relatively quickly.
It was clear that we needed to manage these clusters uniformly, and for the most part, we could do so. For example, if we needed to update cluster-autoscaler in all our clusters, a single commit would have sufficed. However, there was still one outlier.
Even though we were running close to ten EKS clusters at that time, our main cluster, k8s2, which hosted our SaaS platform, continued to serve customers. Our small team, responsible for all our Kubernetes infrastructure, shifted its focus to developing EKS modules. Consequently, the maintenance of k8s2 was relegated to a secondary priority. Once again, our main cluster became outdated, lagging several minor versions behind the EKS clusters.
Our ideal scenario was clear: we aimed to run everything seamlessly on EKS under uniform management. Faced with a new trade-off, we chose to focus our limited time on designing a migration to EKS rather than coordinating an upgrade in k8s2. As a consequence, inconsistencies between our environments started pouring in like rain due to deprecated APIs and new features. We handled those inconsistencies with kustomize patches.
patchesJson6902:
- target:
group: networking.k8s.io
version: v1
kind: 'Ingress'
name: '.*'
patch: |-
- op: replace
path: "/apiVersion"
value: networking.k8s.io/v1beta1
This situation wasn’t sustainable and could quickly spiral out of control. Our main cluster, k8s2, was anchoring us to technical debt.
To compound the issue, k8s2 had a hard limit of 256 nodes. We were using Flannel as our network fabric, with the default size for its pod CIDR network: /16. Out of that network, each node would get its own /24, accounting for a total of 256 nodes. We were already using over 200, and although we had some room for growth, it was a looming concern.
There we were again, having to coordinate a new cluster-to-cluster migration. It felt like we had to migrate k8s1 to k8s2 all over again, but we were in a different state this time.
Throughout our Kubernetes journey, two important things happened. We scaled at a cluster level, running hundreds of services, and the teams using the cluster grew. We could not make this migration the same way because tracking execution across all our teams would have been a nightmare. Instead, we used this as an opportunity to create homegrown tooling and automate.
We always lacked the right “excuse” to implement a service mesh, but we seized the migration as the perfect opportunity to do so. This change would allow our services to communicate with each other regardless of the cluster in which they reside. After a few weeks of research, we settled on using Istio.
In our opinion, it had the right balance between project maturity and community support. We learned the ropes and installed it in k8s2. Additionally, we bootstrapped a new EKS cluster, eks1, in the same region and connected the clusters using an east-west gateway.
However, we still had to incorporate our services into the mesh. We did this semi-manually, namespace by namespace:
if [ "$OP" == "enable" ]; then
kubectl label --overwrite ns "$NS" istio.io/rev=$ISTIO_REVISION
elif [ "$OP" == "disable" ]; then
kubectl label ns "$NS" istio.io/rev-
fi
if [ "$RESTART" == "true" ]; then
for i in $(kubectl -n "$NS" get deploy --no-headers | grep -v '0/0' | cut -d' ' -f1); do
kubectl -n "$NS" rollout restart deploy "$i"
done
fi
We started parallel workloads in eks1, but we needed to make sure validations were done before they started receiving traffic. To control these knobs, we leveraged Istio's traffic control primitives. We set a DestinationRule for each workload to define subsets based on the network they were part of.
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: webapps-ing-ctrl.webapps.svc.cluster.local
spec:
host: webapps-ing-ctrl.webapps.svc.cluster.local
subsets:
- labels:
topology.istio.io/network: k8s2.prd.sfo2
name: k8s2
- labels:
topology.istio.io/network: eks1.prd.sfo2
name: eks1
Additionally, we used a VirtualService for each workload to control which cluster was serving requests. This approach enabled us to slowly ramp up workloads into eks1 to validate that our platform was working as expected before committing all the traffic.
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: webapps-ing-ctrl.webapps.svc.cluster.local
spec:
hosts:
- webapps-ing-ctrl.webapps.svc.cluster.local
http:
- route:
- destination:
host: webapps-ing-ctrl.webapps.svc.cluster.local
subset: k8s2
weight: 0
- destination:
host: webapps-ing-ctrl.webapps.svc.cluster.local
subset: eks1
weight: 100
Given that we had to do this dance for each workload, we automated the process by generating these manifests programmatically.
$ ./bin/generate-migration-manifests \
--src-env-dir environments/staging/us-west-1/k8s2/ \
--dst-env-dir environments/staging/us-west-1/eks1/ \
--kube-ctx k8s2.stg.sfo2 \
--ns agent --svc agent-service
[+] Generating yaml for agent-service.agent in environments/staging/us-west-1/k8s2/agent/agent-service.yaml
[+] Generating yaml for agent-service.agent in environments/staging/us-west-1/eks1/agent/agent-service.yaml
We executed this migration across several weeks, focusing on one namespace at a time. We decided not to do the entire migration in staging and to do it later in production instead because we knew it was a big effort that would span weeks if not months, and we could not afford to lose parity between our environments.
Instead, we migrated a namespace in staging, validated it, and then migrated the same namespace in production. Some namespaces were bigger and more difficult than others, and we would take several days to complete the migration safely. During a namespace migration, the owning team was interrupted minimally to validate that their services were acting normally. We were able to use Istio metrics to validate that the traffic was going to the new cluster, as shown in Figure 4.
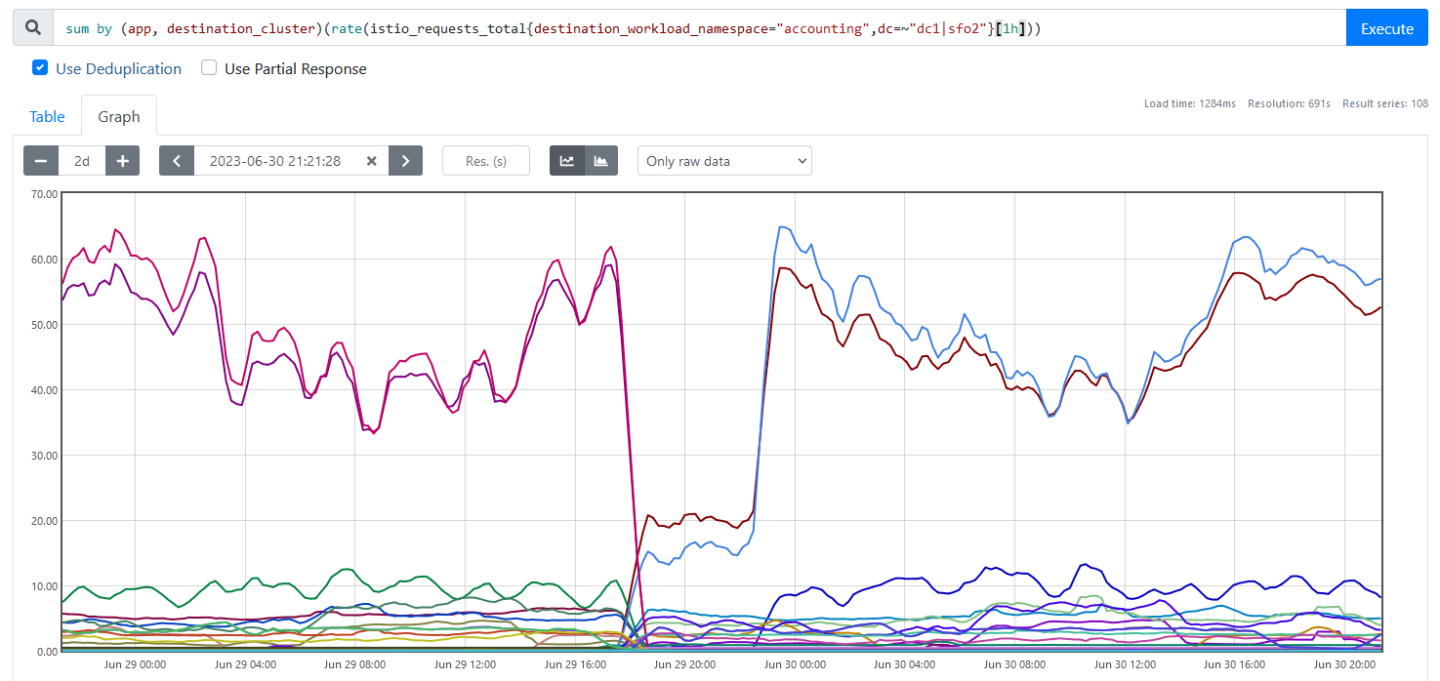
sum by (app, destination_cluster)(rate(istio_requests_total{destination_workload_namespace="accounting",dc=~"dc1|sfo2"}[1h]))
Not everything was smooth sailing. On a few occasions, we had to revert a whole day’s worth of work due to problems running the workloads in eks1. On one occasion, we noticed lag piling up on one of our Kafka clusters. Kafka, a distributed event streaming platform, was holding up events, and the just-migrated workloads in eks1 were not processing them fast enough. After rolling back and analyzing what went wrong, we realized that the ASG in eks1 had a weaker instance type than what we were using in k8s2. Once fixed, we retried that migration, and the new workers in eks1 were able to withstand the pressure from the Kafka workloads.
Another issue arose due to mismatched configurations between the nodes. Our k8s2 nodes had a specific TCP keepalive time that was required to interact with a database. That k8s2 configuration was deep in our Puppet code, and we missed setting it on our managed eks1 nodes. As a result, some pods were timing out in their connections to the database. Naturally, porting said configuration solved the issue.
An additional mishap occurred due to mismatched security groups. A few pods needed to interact with parts of our infrastructure not hosted in Kubernetes and were failing to do so because we missed adding eks1 nodes to their allow-list. Once we identified this situation, we looked for all security groups where k8s2 nodes were being allowed, and we also added eks1 nodes to make sure that no other migrated workload would hit the same problem.
And so, with this approach, even though we faced a few rough patches along the way, we were able to migrate a cluster used by 20+ teams with hundreds of workloads without involving the whole engineering department. We gracefully got away from the old cluster and docked into the safe harbor of our new infrastructure. We left k8s2 safely, which served us well until the very end.
In this article I presented a real-life scenario of an early Kubernetes adopter who significantly expanded their organization and workloads over time. If the team is small, a delicate balance must be kept between sustainably modernizing the infrastructure versus keeping the lights on with day-2 operations. Behind Kubernetes lies a sea of complexity. Managed clusters offer a degree of automation but do not serve as a panacea. Even with these, cluster administrators must ensure manifests remain valid across updates. In a small cluster with few users, the responsibility of updating these manifests can fall to their owners. In larger clusters, automation becomes crucial to avoid a coordination nightmare.
I've often read, with quiet envy, about people smoothly upgrading and migrating entire Kubernetes clusters using a blue-green approach or other sparkly techniques. While I'm convinced of its feasibility, not every organization possesses the necessary maturity to do so. Ours certainly didn't. The trade-offs we chose were appropriate for our circumstances, considering the diversity of our workloads and the tools and techniques available to us at the time. As we navigate these complexities, we keep learning, improving, and moving forward—step by step, cluster by cluster.
