Modern cluster managers such as Kubernetes are architected as a cluster of loosely-coupled controllers, each running as a microservice. In Kubernetes, all the cluster management logic is encoded in different controllers. These controllers include builtin controllers for managing cluster resources and providing management services (e.g., the Kubernetes StatefulSet controller and Pod autoscaler) and custom controllers for managing specific applications (e.g., a Cassandra controller). Today, thousands of controllers are implemented by commercial vendors and open-source communities to extend Kubernetes with new capabilities [8, 13, 15]. All these controllers perform critical operations, such as resource provisioning, software upgrades, configuration updates, and autoscaling, making their correctness paramount.
Achieving controller correctness is fundamentally challenging. Modern cluster managers follow the state-reconciliation principle that each controller continuously monitors a subset of the cluster state and reconciles the current state of the cluster to match a desired state. A reliable controller should reach the desired state starting from any potential cluster state while tolerating unexpected failures, networking interruptions, concurrency and asynchrony issues. Buggy controllers may cause severe failures, including application outage, data loss, and security issues.
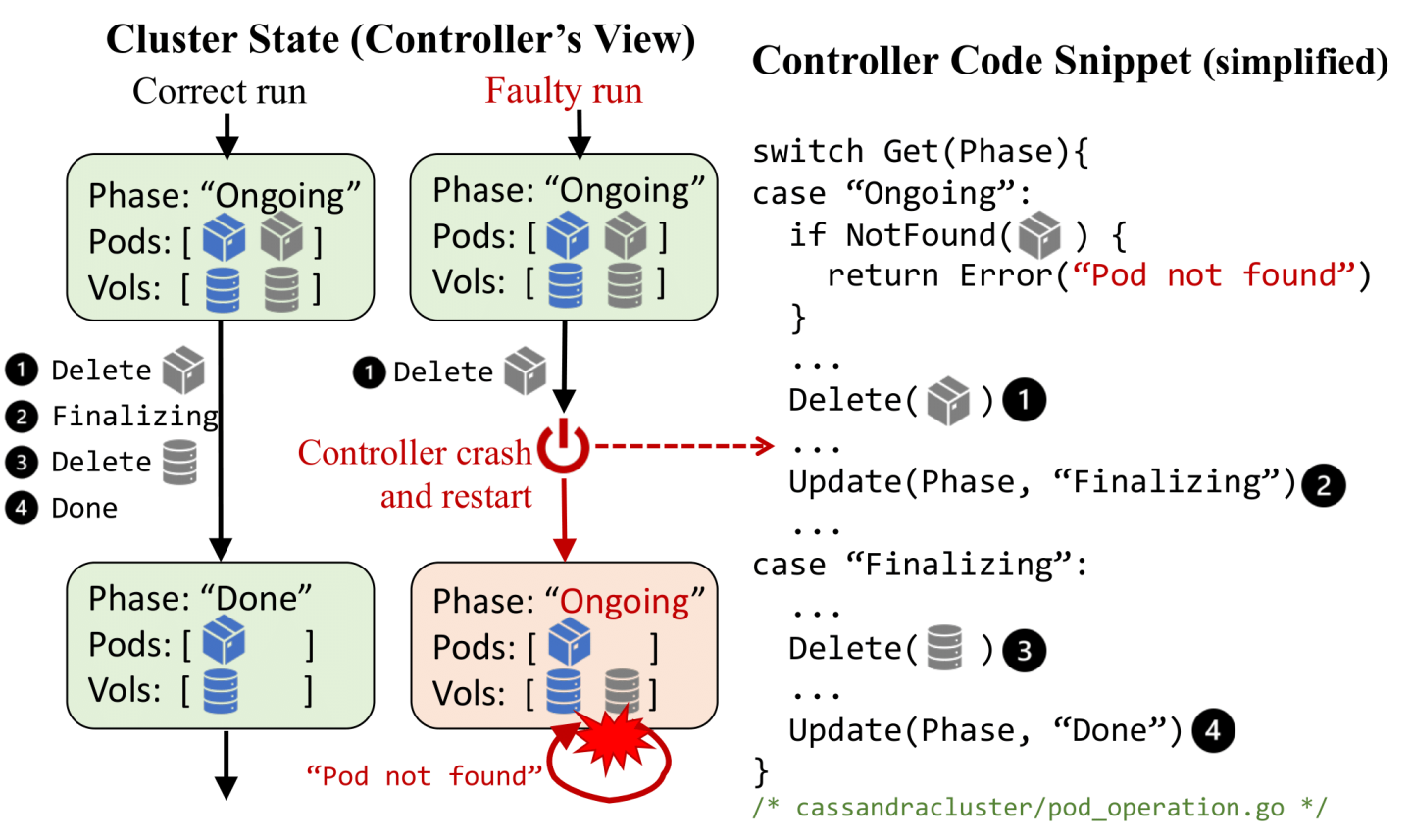
For example, Figure 1 shows a bug in a Kubernetes controller for managing Cassandra [5]. The bug prevents the Cassandra cluster from auto-scaling and leaks storage resources (decommissioned volumes in gray are never deleted). This is because the controller lacks crash safety—it fails to recover from an intermediate state due to a crash between deleting a Cassandra pod and updating the Finalizing phase.
The above crash-safety bug is only one of the myriad kinds of reliability issues that affect controllers. We find that controllers also experience bugs caused by state inconsistencies due to effects of asynchronous operations or uncoordinated concurrent interactions between controllers. For example, a controller might not always observe the latest version of the cluster state and might miss some version of the cluster state [19].
Sieve is a chaos testing tool for cluster management controllers. Sieve is powered by a fundamental insight that a controller’s actions are strictly a function of its view of the current cluster state—a controller constructs its internal state and takes actions to achieve the desired state based on the cluster state it observes. Sieve drives unmodified controllers to their potentially buggy corners by systematically and extensively perturbing the controller’s view of the cluster state. Sieve’s perturbations are realized by injecting faults (e.g., crashes) that controllers should tolerate.
Different from many existing chaos testing tools, Sieve performs exhaustive testing without depending on hypotheses about vulnerable regions in the code where bugs may lie. Sieve tests a controller by exhaustively introducing state perturbations through failures, delays, and reconfigurations. To detect diverse bugs with different causes, Sieve supports three perturbation patterns that expose controllers to 1) intermediate states (Figure 1), 2) stale states (or past cluster states), and 3) unobserved states due to missing some cluster state transitions. Sieve detects both safety and liveness bugs using automatic differential oracles that compare the cluster-state transitions with and without perturbations. Sieve also deterministically reproduces the detected bugs to help developers localize bugs in the source code and continuously iterate on bug fixes.
Sieve has detected 46 new bugs with serious consequences in ten popular Kubernetes controllers. These controllers manage critical cloud applications, including Cassandra, MongoDB and ZooKeeper. For each tested controller, Sieve’s testing finishes within seven hours (a nightly run) on a cluster of 11 machines.
Sieve is publicly available at https://github.com/sieve-project/sieve.
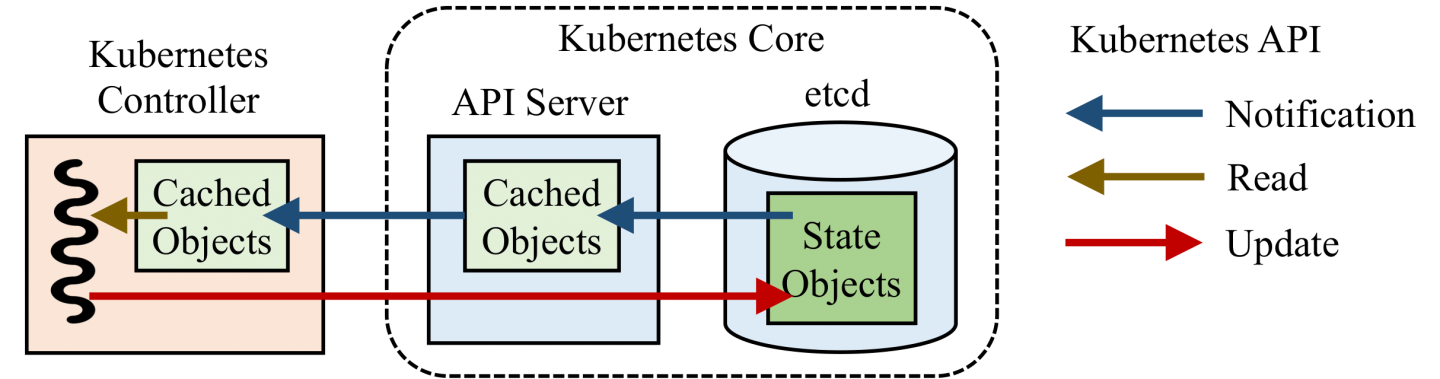
All Kubernetes controllers follow the state-reconciliation principle. Concretely, in Kubernetes, the cluster state is represented as a collection of objects stored in a distributed datastore, i.e., etcd in most cases. The datastore is logically centralized as it uses a consensus protocol to achieve consistency. Every entity in the cluster has a corresponding object in the cluster state, including pods, volumes, nodes, and groups of applications. All controllers interact with the cluster state via an ensemble of API servers using a REST API. The controllers continuously monitor a part of the cluster state and perform state reconciliation whenever the current state does not match the desired state. The controllers perform reconciliation by querying and manipulating the state objects via an API server. When querying an object, a controller might issue a quorum read on etcd for consistency, or directly read from the API server’s local cache for performance. Figure 2 illustrates how a controller interacts with the cluster state typically.
The key idea of Sieve is to automatically and extensively perturb an unmodified controller’s view of the cluster states in ways it is expected to tolerate. Sieve leverages the fundamental nature of state-reconciliation systems – these systems often have a simple and highly introspectable state-centric interface with which controllers interact with the cluster state. Such interfaces essentially do no more than reads and writes, or receive notifications regarding state-object changes. All objects share a common schema, which makes any arbitrary object highly introspectable. In Kubernetes, the state-centric interface is the REST API (in client-go [2]) used by controllers to Get, List, Create, Update and Delete state objects, and all state objects have an identical set of fields representing their metadata (ObjectMeta). This enables a degree of automation that is hard to achieve otherwise.
Sieve performs exhaustive reliability testing. For each test workload, Sieve first generates a reference run by running the workload without any perturbation. Sieve then analyzes the reference run to generate test plans. A test plan describes a concrete perturbation, including what faults to inject and when to inject them to effectively drive the controller to see the target cluster state. For example, to test controllers against intermediate cluster states, Sieve generates test plans that encode each potential point to inject a controller crash. When testing the Cassandra controller in Figure 1, Sieve covers the crash points including after deleting the pod, updating the phase and deleting the volume.
To achieve high test efficiency, Sieve prunes redundant or futile test plans. Sieve avoids a test plan if it is clear that it cannot causally lead to a new target cluster state. As an example, when introducing intermediate states, Sieve crashes the controller only after effective state updates – ineffective updates, such as deleting a non-existing object, do not introduce any new cluster state. Sieve’s test pruning technique reduces test plans by 46.7%–99.6% in our experience.
To help developers debug test failures, Sieve deterministically reproduces each bug triggered by its perturbation by precisely replaying the bug-triggering fault injection. To reproduce the bug in Figure 1, Sieve injects a crash right after the controller deletes the pod and before it updates the phase to Finalizing in each repeated test run with the same test plan. Sieve’s reproducibility helps us localize the bug in the source code and develop a patch that fixes this bug. To precisely control the timing of fault injection, Sieve automatically instruments the client-go library and recompiles the controller with the instrumented library (for this reason, the controller source code must be available).
The key techniques that power Sieve’s bug finding ability are its 1) perturbation patterns for triggering diverse bugs with different causes, and 2) differential test oracles for catching bugs that cause safety and liveness violations. We now present how Sieve’s perturbation patterns and differential test oracles work.
2.1 Perturbation Patterns
Sieve’s perturbations are produced by injecting targeted faults (e.g., crashes, delays, and connection changes) when specific cluster-state changes (triggering conditions) happen. Notably, the perturbation strategy allows Sieve to decouple policy from mechanism. The decoupling makes it easy to extend existing policies or add new policies by orchestrating the underlying perturbation mechanisms. Specifically, a policy defines a view Sieve exposes to the controller at a particular condition, while the mechanism specifies how to inject faults to create the view. Sieve automatically generates test plans for each policy; each test plan introduces a concrete perturbation based on a specification of a triggering condition and a fault to inject when that condition happens.
Sieve currently supports three patterns (or policies) to perturb a controller’s view:
- intermediate states,
- stale states, and
- unobserved states.
They represent valid inconsistencies in the view that a controller could see due to common faults as well as the inherent asynchrony of the overall distributed system. Note that these are not the only patterns in which faults can occur, but cover a broad range of faults that a component in a distributed system is expected to handle gracefully. Sieve can be extended to incorporate other patterns in the future.
Intermediate states. Intermediate states occur when controllers fail in the middle of a reconciliation before finishing all the state updates they would have otherwise issued. After recovery (e.g., Kubernetes automatically starts a new instance of a crashed controller), the controller needs to resume reconciliation from the intermediate state left behind.
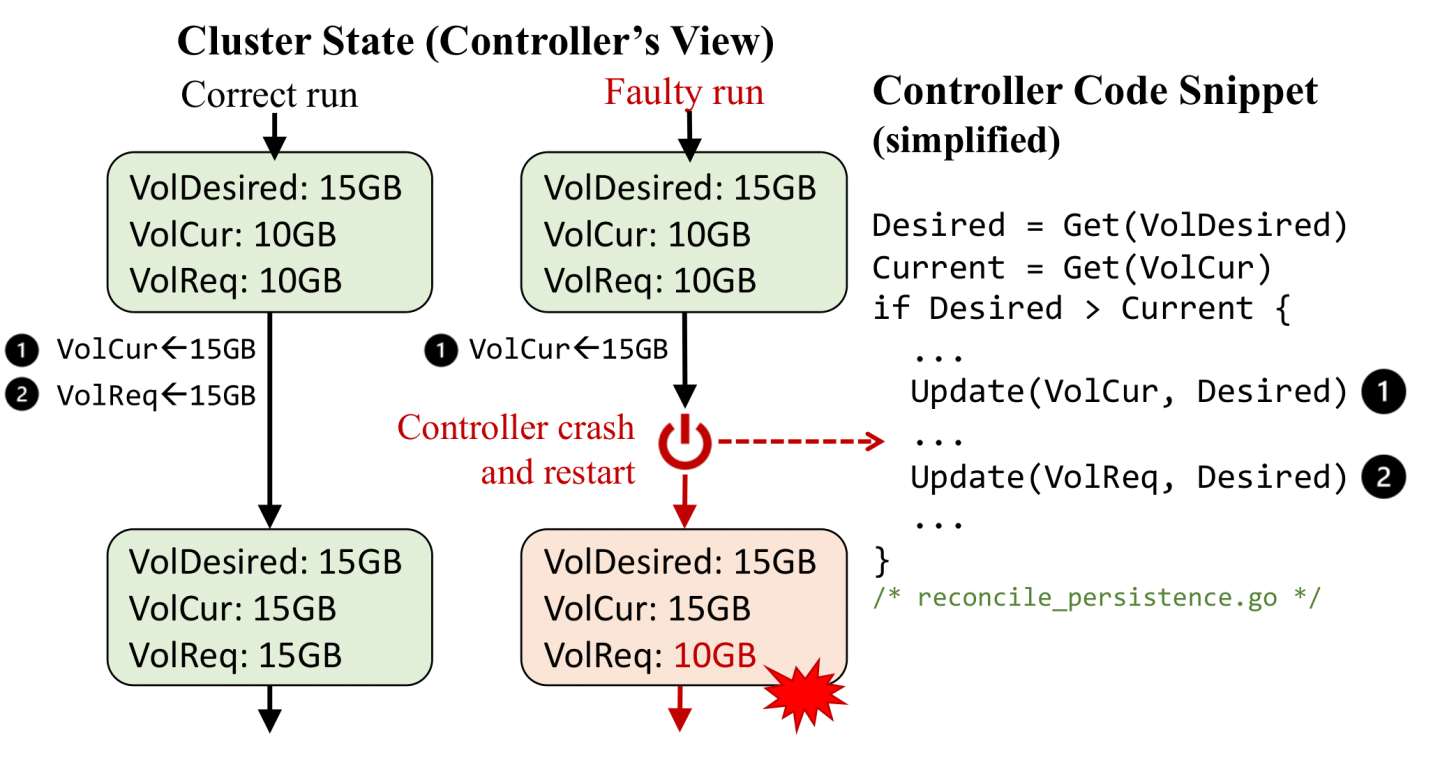
Figure 3 illustrates how Sieve tests the official RabbitMQ controller with intermediate-state perturbations and reveals a new bug. The test workload attempts to resize the storage volume from 10GB to 15GB. The resizing is implemented with two updates: 1) updating VolCur to 15GB; 2) updating VolReq to 15GB which triggers Kubernetes to resize the volume. The controller issues updates when VolCur is smaller than the desired volume size. During testing, Sieve crashes the controller between the two updates, which creates an intermediate state where VolCur is updated, but VolReq is not. The controller cannot recover from the intermediate state and the resizing never succeeds. The bug has been fixed with 700+ lines of Go code to revamp the volume resizing logic. In addition, the developers added eight new tests along with the fix to exercise how the controller handles different intermediate states, which is what Sieve performs automatically.
Stale states. Controllers often operate on stale states, due to asynchrony and the extensive uses of caches for performance and scalability. As shown in Figure 2, controllers do not directly interact with the strongly consistent data stores, but are connected with API servers. The states cached at API servers could be stale due to delayed notifications. Controllers are expected to tolerate stale views that lag behind the latest states maintained in the data store.
Tolerating stale views correctly is nontrivial. For example, a Kubernetes controller’s view may “time travel” to a state it observed in the past. Time traveling occurs when there are multiple API servers operating in a high-availability setup, when the controller reconnects to a stale API server that has not yet seen some updates to the cluster state. The reconnection can be triggered by failover, load balancing, or reconfigurations. Controllers are expected to avoid updating the cluster state wrongly based on its stale view of the cluster state. For example, when sending a deletion request the controller can piggyback its most recently observed cluster state’s resource version (in the preconditions), and ask etcd to check the freshness of the resource version before the deletion takes effect.
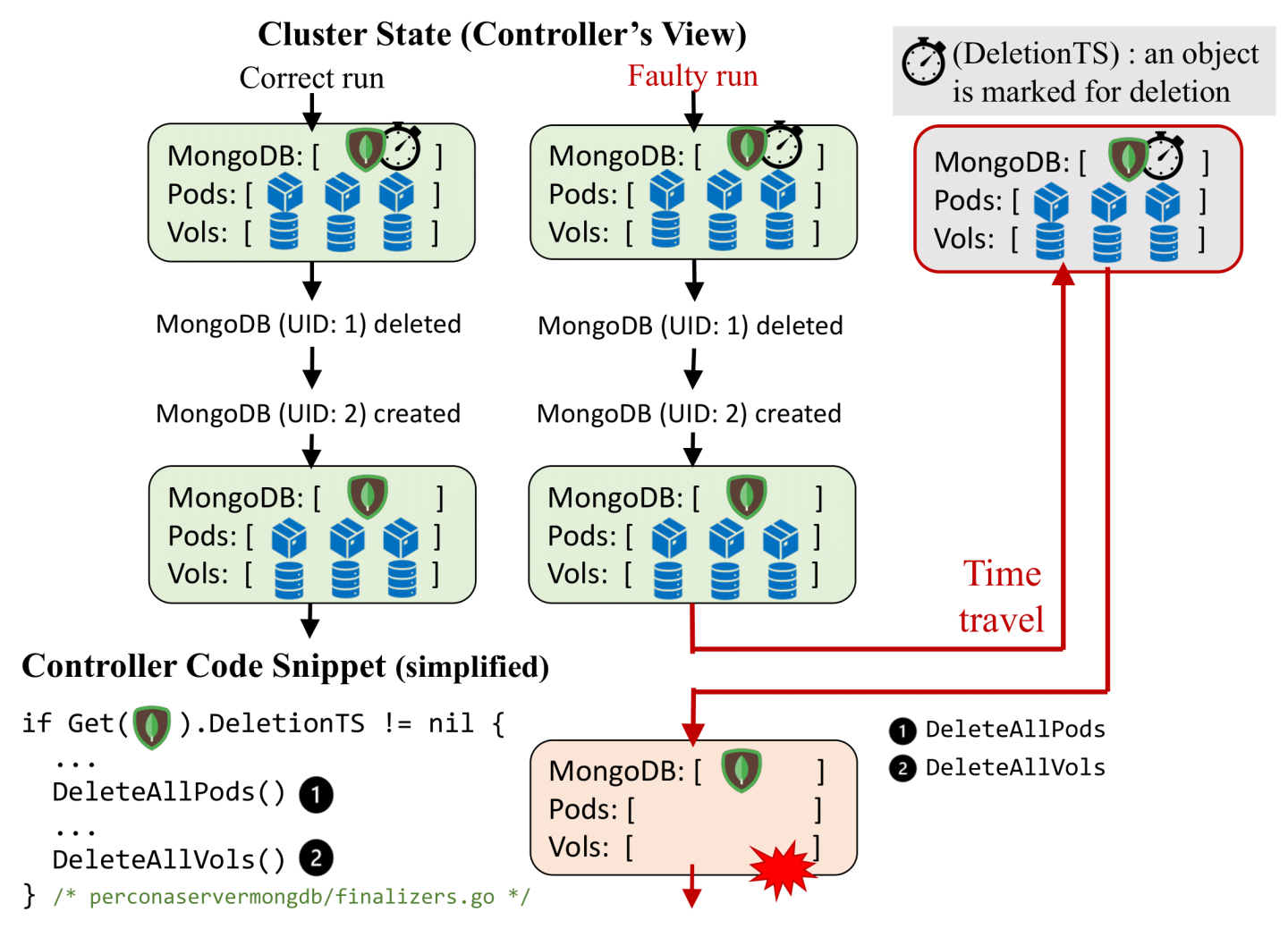
Figure 4 illustrates how Sieve tests Percona’s MongoDB controller with stale-state perturbation and reveals a new bug that leads to both application outages and data loss. To support graceful MongoDB cluster shutdowns, the controller waits to see a non-nil deletion timestamp (DeletionTimestamp) field attached to the state object representing the MongoDB cluster (a common practice to give systems time to react to an impending deletion [3]). When the controller sees this change, it deletes all the pods and volumes of the MongoDB cluster.
Sieve drives the controller to mistakenly delete a live MongoDB cluster by introducing a time-travel perturbation. With a workload that first shuts down a MongoDB cluster and then recreates a new instance of the same cluster, Sieve waits till the cluster is recreated and then introduces a time-travel perturbation. The perturbation causes the controller to see the deletion timestamp being applied to the already-deleted cluster. Consequently, the controller mistakenly shuts down the newly created cluster. This revealed that the controller should be checking for the UIDs of clusters, not just their names.
Unobserved states. By design, controllers may not observe every cluster-state change in the system. The full history of changes made to the cluster state is prohibitively expensive to maintain and expose to clients [19]. Controllers are hence expected to be designed as level-triggered systems (opposed to being edge-triggered), i.e., a controller’s decision must be based on the currently observable cluster state (level) [9], not on seeing every single change to the cluster state (edge).
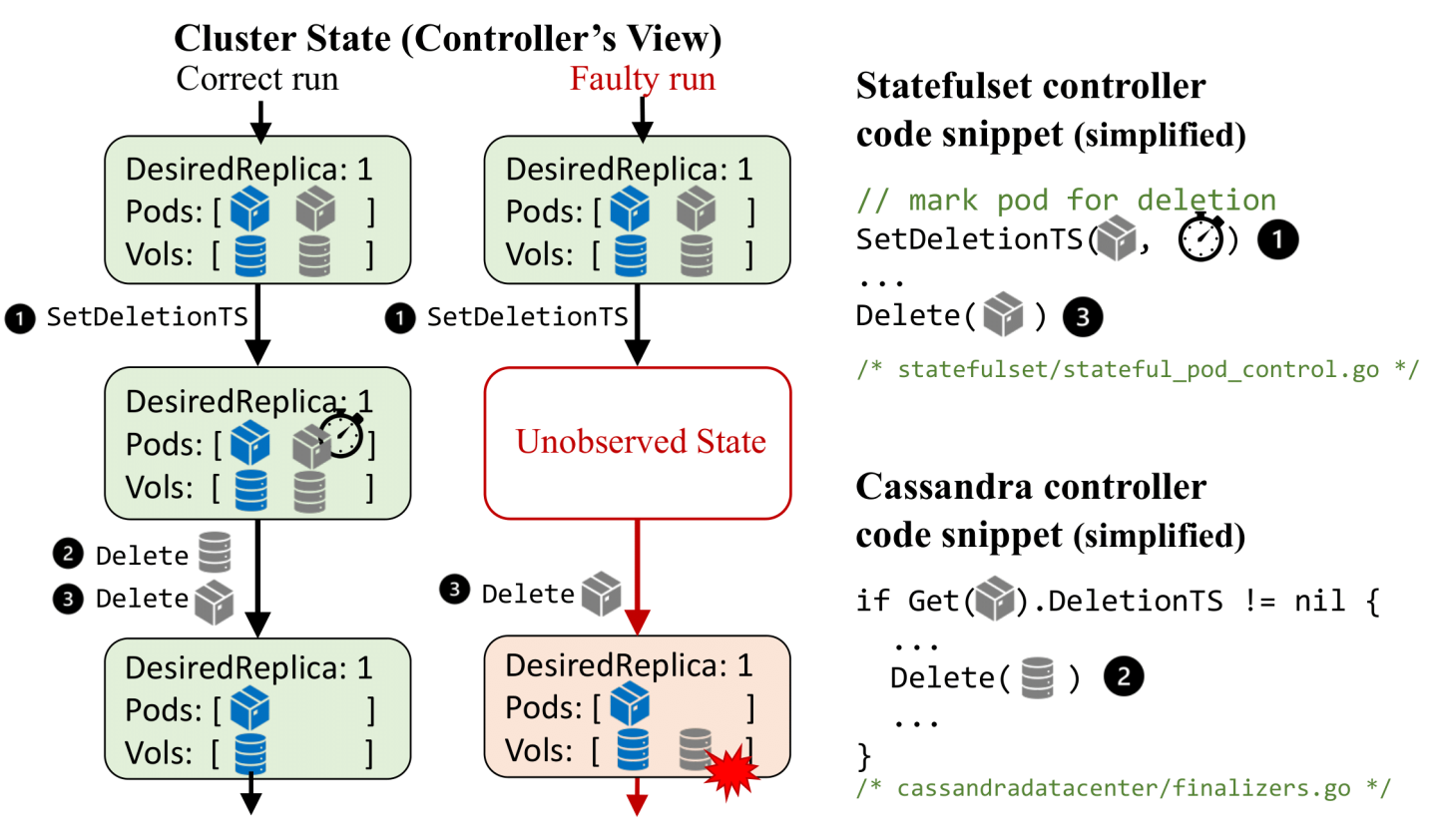
Figure 5 illustrates how Sieve tests Instaclustr’s Cassandra controller using unobserved-state perturbations and reveals a new bug that leads to resource leaks and service failures. The test workload first scales down and then scales up storage volumes of the Cassandra cluster. During scale-down, the controller removes volumes when it learns that the corresponding pods were marked for deletion (a non-nil deletion timestamp field is set on the pod object, similar to the previous example). The pods’ lifecycles (including deletions) are managed by a built-in controller called a StatefulSet controller. Sieve pauses notifications to the Cassandra controller for a window such that it does not see these deletion marking events by the StatefulSet controller. This causes the Cassandra controller to not delete the corresponding volumes even though it has the right information to make that call (i.e., its view has volumes created by it that do not have pods attached to them).
Hence, the volume never gets deleted, leaking the storage resource. The bug also prevents the controller from scaling the Cassandra cluster – newly-created pods try to reuse the dangling volumes and cannot rejoin using the cluster metadata already in them (as it represents a node that was decommissioned). The bug has been fixed by adding finalizers – a coordination mechanism in Kubernetes that allows the Cassandra controller to complete the required cleanup operations before the pods can be deleted.
2.2 Differential Test Oracles
Sieve has generic, effective oracles to automatically detect safety and liveness issues. The oracles detect buggy controller behavior based on the cluster states during and at the end of the test run.
In our experience, many buggy controller behaviors do not show immediate or obvious symptoms (e.g., crashes, hangs, and error messages). Instead, they lead to data loss, security issues, resource leaks, and unexpected application behavior which is hard to check. We therefore develop differential test oracles that compare cluster states in a reference run versus those in test runs—with inconsistencies typically indicating buggy behavior.
We found that Sieve’s differential oracles vastly outperform developer-written assertions in the test suites of the controllers we evaluated, because Sieve’s oracles systematically examine all the state objects and their evolution during testing. It is challenging for developers to manually codify oracles that comprehensively consider the large number of relevant states.
Note that Sieve also implements regular error checks for obvious anomalies, including exceptions, error codes and timeouts. Developers can also add domain-specific oracles.
2.2.1 Checking End States
Sieve systematically checks the end state after running a workload. Specifically, our oracles check the count of state objects by type and the field values of all the objects. It compares the end state of the test run versus the reference run. Sieve fails the test if it finds inconsistencies between the end states and prints human-readable messages to pinpoint inconsistencies.
For example, in a MongoDB controller bug [11], the controller fails to create an SSL certificate used for securing communications inside the MongoDB cluster. This causes the controller to fall back to insecure communications. Such security issues do not manifest in the form of crashes or error messages. Sieve however automatically catches the bug, because the certificate object in the faulty run does not exist in the cluster state, which is different from a normal run.
2.2.2 Checking State-Update Summaries
Besides the end state, Sieve also checks how the controller updates the cluster state over time. It does so by comparing summaries of constructive and destructive state updates for each object (e.g., Create and Delete operations). Such checks are complementary to the end-state checks, because a correct end state does not imply that the controller behavior is always correct during the test. We find that buggy behavior can end in correct states (same as in the reference runs).
For example, a NiFi controller bug [12] causes the controller to fail to reload configuration files, but the end state is the same as a normal run. Sieve flags this by noting the NiFi pod receives a Create and a Delete operation (to reload the configuration) in the normal run, but neither appears in the faulty run.
2.2.3 Dealing with Nondeterminism
Sieve’s differential oracles can introduce false alarms because the shape of a state object (the set of fields and their values) might be nondeterministic. Sieve identifies nondeterministic field values by running the test workloads without perturbation multiple times, and then comparing the values of each field in each state object. If a field has nondeterministic values (typically IP addresses, timestamps, or even random port numbers), Sieve masks the field values when comparing the states. Note that Sieve can still spot unexpected changes to the set of fields on the object (e.g., missing deletion timestamp fields).
We have applied Sieve to ten popular controllers from the Kubernetes ecosystem for managing widely-used cloud systems, including Cassandra, MongoDB and ZooKeeper. The controllers are either developed by the official development team of the corresponding system, or by companies that have production-grade offerings around said systems. To test each controller using Sieve, we provide 2–5 basic, representative end-to-end test workloads. Each workload exercises a feature of the controller (e.g., deployment, scaling, reconfiguration).
Sieve finds a total of 46 new bugs in the evaluated controllers. Those bugs include 11 intermediate-state bugs, 19 stale-state bugs, 7 unobserved-state bugs, and 9 bugs indirectly detected by Sieve during testing. Sieve finds new bugs in all the evaluated controllers. We have reported all these bugs. So far, 35 of them have been confirmed and 22 have been fixed. No bug report was rejected. Many bugs have severe consequences, such as application outages, security issues, service failures, and data loss. The Sieve project maintains the list of found bugs [1].
The original Sieve paper [17] was published in 2022 and we have continued working on testing Kubernetes controllers since that. After Sieve, we built Acto [6, 7], an end-to-end functional testing tool for controllers. Acto does not perform fault injection testing, but it complements Sieve by automatically generating high-coverage, representative test workloads that can be used by Sieve.
After seeing many bugs found by Sieve and Acto, we started to explore a new approach to guarantee controller correctness and reliability. Anvil [16, 18] is a framework that allows developers to use formal verification to build clean-slate controllers that are proved to be free of many types of bugs found by Sieve and Acto. We used Sieve and Acto to empirically evaluate the verified controllers built using Anvil.
Ensuring the reliability of Kubernetes controllers is a pressing and challenging problem. We present Sieve, a chaos testing technique for Kubernetes controllers. Sieve performs exhaustive and deterministic testing and is effective in finding bugs. Our goal is to make Sieve a part-and-parcel of every controller developers’ toolkit, and to harden the growing number of controllers that power today’s data centers. Sieve is publicly available at https://github.com/sieve-project/sieve. We refer readers interested in more technical details and evaluation results to the original paper which is available at https://github.com/sieve-project/sieve/blob/main/docs/paper-osdi.pdf.







