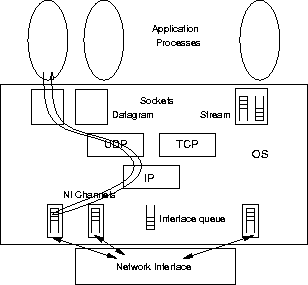
In this section, we present the design of our network subsystem architecture based on lazy receiver processing (LRP). We start with an overview, and then focus on details of protocol processing for UDP and TCP.
The proposed architecture overcomes the problems discussed in the
previous section through a combination of techniques: (1) The IP
queue
is replaced with a per-socket
queue that is shared with the network interface (NI). (2) The
network interface demultiplexes incoming packets according to their
destination socket, and places the packet directly on the appropriate
receive queue . Packets destined for a socket with a full receiver
queue are silently discarded (early packet discard). (3) Receiver
protocol processing is performed at the priority of the receiving
process. (4) Whenever the
protocol semantics allow it, protocol processing is performed lazily,
in the context of the user process performing a receive system call.
Figure 2 illustrates the LRP architecture.
. Packets destined for a socket with a full receiver
queue are silently discarded (early packet discard). (3) Receiver
protocol processing is performed at the priority of the receiving
process. (4) Whenever the
protocol semantics allow it, protocol processing is performed lazily,
in the context of the user process performing a receive system call.
Figure 2 illustrates the LRP architecture.
There are several things to note about the behavior of this architecture. First, protocol processing for a packet in many cases does not occur until the application requests the packet in a receive system call. Packet processing no longer interrupts the running process at the time of the packet's arrival, unless the receiver has higher scheduling priority than the currently executing process. This avoids inappropriate context switches and can increase performance.
Second, the network interface separates (demultiplexes) incoming traffic by destination socket and places packets directly into per-socket receive queues. Combined with the receiver protocol processing at application priority, this provides feedback to the network interface about application processes' ability to keep up with the traffic arriving at a socket. This feedback is used as follows: Once a socket's receive queue fills, the NI discards further packets destined for the socket until applications have consumed some of the queued packets. Thus, the NI can effectively shed load without consuming significant host resources. As a result, the system has stable overload behavior and increased throughput under high load.
Third, the network interface's separation of received traffic, combined with the receiver processing at application priority, eliminates interference among packets destined for separate sockets. Moreover, the delivery latency of a packet cannot be influenced by a subsequently arriving packet of equal or lower priority. And, the elimination of the shared IP queue greatly reduces the likelihood that a packet is delayed or dropped because traffic destined for a different socket has exhausted shared resources.
Finally, CPU time spent in receiver protocol processing is charged to the application process that receives the traffic. This is important since the recent CPU usage of a process influences the priority that the scheduler assigns a process. In particular, it ensures fairness in the case where application processes receive high volumes of network traffic.
Early demultiplexing--a key component of LRP's design--has been used in many systems to support application-specific network protocols [11, 23], to avoid data copying [6, 21], and to preserve network quality-of-service guarantees for real-time communication [10]. Demultiplexing in the network adaptor and multiple NI channels have been used to implement low-latency, high-bandwidth, user-level communication [1, 5]. Protocol processing by user-level threads at application priority has been used in user-level network subsystem implementations [10, 11, 23]. What is new in LRP's design is (1) the lazy, delayed processing of incoming network packets, and (2) the combination and application of the above techniques to provide stability, fairness, and increased throughput under high load. A full discussion of related work is given in Section 5.
It is important to note that the two key techniques used in LRP--lazy protocol processing at the priority of the receiver, and early demultiplexing--are both necessary to achieve stability and fairness under overload. Lazy protocol processing trivially depends on early demultiplexing. To see this, observe that the receiver process of an incoming packet must be known to determine the time and priority at which the packet should be processed.
Conversely, early demultiplexing by itself is not sufficient to provide stability and fairness under overload. Consider a system that combines the traditional eager protocol processing with early demultiplexing. Packets are dropped immediately in case their destination socket's receive queue is full. One would expect this system to remain stable under overload, since traffic arriving at an overloaded endpoint is discarded early. Unfortunately, the system is still defenseless against overload from incoming packets that do not contain valid user data. For example, a flood of control messages or corrupted data packets can still cause livelock. This is because processing of these packets does not result in the placement of data in the socket queue, thus defeating the only feedback mechanism that can effect early packet discard.
In addition, early demultiplexing by itself lacks LRP's benefits of reduced context switching and fair resource allocation, since it shares BSD's resource accounting and eager processing model. A quantitative comparison of both approaches is given in Section 4. We proceed with a detailed description of LRP's design.