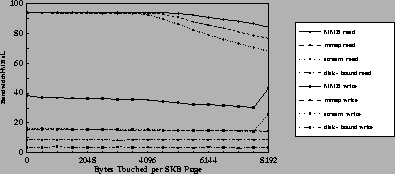
Figure 4 compares bandwidths delivered to a user process reading and writing files sequentially through the stream, mmap, and MMB interfaces. To show the effect of user program activity, we report bandwidths and CPU utilizations as the test program touches varying amounts of the data on each page. The benchmark repeatedly accesses a file that overflows the local file cache, varying the size read or written for each page from one word up to the 8K page size. We averaged ten iterations with 120,000 page accesses, moving just under a gigabyte of data to or from the process for each test. Variance is negligible for all tests.
The read tests show that bandwidth starts high and decreases as the test program accesses more of the data. The highest bandwidths are delivered at the left end of the graph; these are sparse read tests in which the application reads and loads only one word of each fetched page. Given the excellent memory system bandwidth on the Miata, the three interfaces deliver the same bandwidth (96 MB/s) until about half the data is touched. Until this point, every access stalls waiting for data to arrive and interface overheads are masked by read-ahead. In comparison, NFS reads from server memory at 13.5 MB/s on the same platform (using standard Myrinet firmware and sufficient I/O daemons); GMS with read-ahead enabled delivers 25 MB/s using IP/Myrinet with the standard firmware rather than Trapeze.
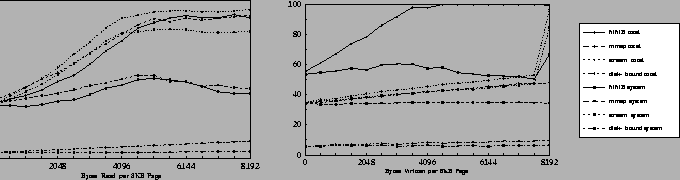
Figure 5 shows CPU utilizations for the same experiments. The system overhead of stream rises quickly as the program touches more of its data and the read and write system calls copy more data in and out of the user process. In contrast, mmap and MMB avoid the copy, and the system overhead stays relatively flat (the hump at 3-5KB appears to be due to the combined effects of high bandwidth and memory system contention from the user process). In the dense read experiments at the right end of the graphs, bandwidth delivered through stream drops to 68 MB/s, as the saturated 500 MHz Alpha CPU spends 80% of its time executing I/O code in the kernel. In contrast, under MMB GMS/Trapeze still delivers almost 84 MB/s, leaving 59% of the CPU time free for the application to process the data. However, simply loading each word up to the CPU saturates the system at these speeds, due to memory system delays. For all three interfaces this experiment is limited by CPU and memory bandwidth rather than the network.
We ran the write tests with Alcor as the client, since its I/O system delivers full send bandwidth. While all tests benefit from zero-copy asynchronous writes (write-behind), file write bandwidths are much lower than read bandwidths for three reasons. First, in the partial-write tests, the kernel must fetch each page (or zero it) before modifying it. Second, these reads do not benefit from read-ahead, since partial sequential writes are rare in practice. Third, Alcor has a slower CPU, its I/O system can receive at only 66 MB/s, and its memory system exacerbates overheads: an Alcor transmitting at full speed delivers less than 25% of its memory system bandwidth to the CPU. Using raw Trapeze, an Alcor can send raw 8KB payloads at 105 MB/s, but the bandwidth drops to 58 MB/s if the sender overwrites each payload buffer before sending it.
For partial writes, MMB delivers the highest bandwidth because it prefetches implicitly on each block access. The bandwidth/overhead spike for the dense write tests at the right end of the graphs occurs because the test program overwrites all of the data, and it is no longer necessary to read each page before writing it. While stream and MMB (using the MAP_OVERWRITE flag) recognize this case, mmap cannot detect the full-block write in advance, and continues to read before writing. Stream delivers 26 MB/s for dense writes on Alcor, while MMB delivers the peak of 46 MB/s (79% of the platform maximum for this test) since it does not copy the data and also avoids fetching or zeroing the pages before they are overwritten.