Software libraries are a common mechanism for re-using code. Like a domain-specific language, libraries can provide high-level abstractions that empower the programmer and hide implementation details. Unlike a domain-specific language, libraries do not introduce new syntax and receive no direct support from the compiler. These differences have two consequences:
Our approach to mitigating these problems is to give libraries some of the compiler support enjoyed by domain-specific languages. The key is an annotation language that captures expert knowledge about libraries and enables our compiler to customize library implementations for different situations. Library users can then focus on application design, relying on our compiler to optimize performance.
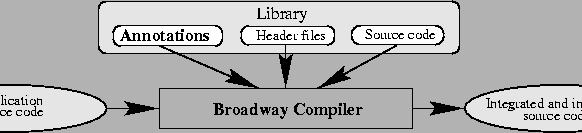
Figure ![]() shows the overall architecture of our system. The
annotations are supplied by a library expert in a separate specification file
that accompanies the usual header files and source code. The annotations
convey two kinds of information about library routines: (1) basic dataflow
information, which is sometimes difficult to obtain through static analysis,
and (2) high level domain-specific information. Our compiler, which we
have named the Broadway compiler, reads the annotations and applies a series
of source-to-source transformations to both the library and application
source. The result is an integrated system of library and application code,
which is ready to be compiled and linked using conventional tools.
shows the overall architecture of our system. The
annotations are supplied by a library expert in a separate specification file
that accompanies the usual header files and source code. The annotations
convey two kinds of information about library routines: (1) basic dataflow
information, which is sometimes difficult to obtain through static analysis,
and (2) high level domain-specific information. Our compiler, which we
have named the Broadway compiler, reads the annotations and applies a series
of source-to-source transformations to both the library and application
source. The result is an integrated system of library and application code,
which is ready to be compiled and linked using conventional tools.
Our system offers many practical benefits. First, the annotations are specified in a separate file from the library source, so our approach applies to existing libraries and existing applications. Second, the annotations describe the library, not the application, so the application programmer does nothing more than use the Broadway Compiler in place of a standard C compiler. Finally, the non-trivial cost of writing the library annotations can be amortized over many applications.
When applied to a Cholesky factorization program that uses the PLAPACK parallel linear algebra library [25], our system improves performance by 26% for large matrices and 195% for small matrices. Both the library and application are written in ANSI C, and neither has been modified to facilitate our results. This paper will explain how our solution is able to obtain these results. While these same optimizations could be performed manually by using a wider interface and expert knowledge of the PLAPACK implementation, our approach offers significant advantages:
The performance improvements mentioned above cannot be obtained with conventional compiler technology because the optimizations require semantic information about the PLAPACK implementation that cannot be derived automatically. For example, one transformation requires knowledge of a PLAPACK object's data distribution. This information is implicitly represented in the values of four object attributes and the value of a global variable. To further complicate matters, PLAPACK is written in C and is difficult to analyze because of its pervasive use of pointers. In addition, certain def/use information is impossible to obtain because PLAPACK makes calls to the sequential BLAS library [11], whose source code is unavailable.
The primary contributions of this paper are (1) the introduction of a new technique for optimizing software libraries, (2) the demonstration that this technique provides performance benefits when applied to a production-quality library, and (3) an evaluation of our annotation language based on experiments with PLAPACK applications.
This paper is organized as follows. Section ![]() contrasts our
work with related efforts. Section
contrasts our
work with related efforts. Section ![]() describes our
annotation language and its design philosophy. Section
describes our
annotation language and its design philosophy. Section ![]() explains our compilation strategy, and Section
explains our compilation strategy, and Section ![]() offers an
empirical evaluation of our language. Finally, we and draw conclusions and
discuss future work.
offers an
empirical evaluation of our language. Finally, we and draw conclusions and
discuss future work.