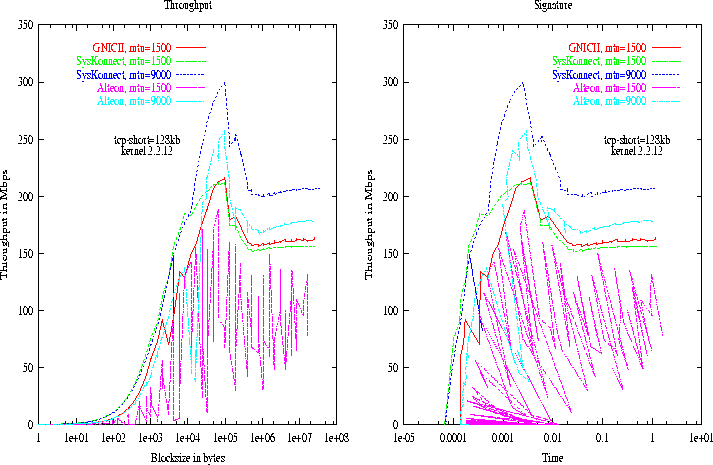
Figure 3: GNIC-II, Alteon, & SysKonnect: LAM Throughput and Latency
Figure 4: GNIC-II, Alteon & SysKonnect: MPICH Throughput and Latency
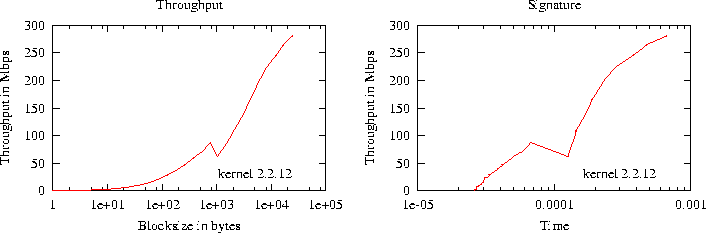
Figure 5: GNIC-II: MVICH Throughput and Latency
In this section, we present and compare the performance of LAM, MPICH, and MVICH on a Gigabit Ethernet network. Before moving on to discuss the performance results of LAM and MPICH, it is useful to first briefly describe the data exchange protocol used in these two MPI implementations. The choices taken in implementing the protocol can influence the performance as we will see later in the performance graphs.
Generally, LAM and MPICH use a short/long message protocol for communication. However, the implementation is quite different. In LAM, a short message consisting of a header and the message data is sent to the destination node in one message. And, a long message is segmented into packets with the first packet consisting of a header and possibly some message data sent to the destination node. Then, the sending node waits for an acknowledgment from the receiver node before sending the rest of the data. The receiving node sends the acknowledgment when a matching receive is posted. MPICH (P4 ADI) implements three protocols for data exchange. For short messages, it uses the eager protocol to send message data to the destination node immediately with the possibility of buffering data at the receiving node when the receiving node is not expecting the data. For long messages, two protocols are implemented - the rendezvous protocol and the get protocol. In the rendezvous protocol, data is sent to the destination only when the receiving node requests the data. In the get protocol, data is read directly by the receiver. This choice requires a method to directly transfer data from one process's memory to another such as exists on parallel machines.
All the LAM tests are conducted using the LAM client to client (C2C) protocol which bypasses the LAM daemon. In LAM and MPICH, the maximum length of a short message can be configured at compile time by setting the appropriate constant. We configured the LAM short/long messages switch-over point to 128KB instead of the default 64KB. For MPICH, we used all the default settings. Figure 3 shows LAM throughput and latency graphs. And, Figure 4 shows MPICH throughput and latency graphs.
For LAM using MTU size of 1500 bytes, the maximum attainable
throughput is about 216 Mbps, 188 Mbps, and 210 Mbps with latency of
140 ![]() secs, 194
secs, 194 ![]() secs, and 66
secs, and 66 ![]() secs for the GNIC-II,
ACEnic, and SK-NET respectively. For MPICH using MTU size of 1500,
the maximum attainable throughput is about 188 Mbps, 176 Mbps, and
249 Mbps with latency of 142
secs for the GNIC-II,
ACEnic, and SK-NET respectively. For MPICH using MTU size of 1500,
the maximum attainable throughput is about 188 Mbps, 176 Mbps, and
249 Mbps with latency of 142 ![]() secs, 239
secs, 239 ![]() secs and 99
secs and 99 ![]() secs
for the GNIC-II, ACEnic, and SK-NET respectively. Since LAM and MPICH
are layered above TCP/IP stacks, one would expect only a small
decrease in performance. However, the amount of performance
degradation in LAM and MPICH as compared to the TCP/IP performance is
considerable. For LAM, the performance drop of approximately 42%,
38% and 41% for GNIC-II, ACEnic, and SK-NET respectively. And, the
performance drop for MPICH is approximately 49%, 42%, and 25% for
GNIC-II, ACEnic, and SK-NET respectively.
secs
for the GNIC-II, ACEnic, and SK-NET respectively. Since LAM and MPICH
are layered above TCP/IP stacks, one would expect only a small
decrease in performance. However, the amount of performance
degradation in LAM and MPICH as compared to the TCP/IP performance is
considerable. For LAM, the performance drop of approximately 42%,
38% and 41% for GNIC-II, ACEnic, and SK-NET respectively. And, the
performance drop for MPICH is approximately 49%, 42%, and 25% for
GNIC-II, ACEnic, and SK-NET respectively.
Changing MTU to a larger size improves LAM performance somewhat. For LAM, the maximum attainable throughput is increased by approximately 42% for SK-NET and by approximately 36% for the ACEnic with MTU of 9000 respectively. However, changing MTU to a bigger size decreases MPICH performance. For MPICH, the maximum attainable throughput drops by approximately 7% for an SK-NET and by approximately 15% for an ACEnic with MTU of 9000.
In all cases, increasing the size of the MTU also increases the
latency slightly except in the case of the test on MPICH using the ACEnic.
In particular, the latency of LAM is approximately 69 ![]() secs for
SK-NET and 141
secs for
SK-NET and 141 ![]() secs for ACEnic. And, the latency of MPICH is
approximately 100
secs for ACEnic. And, the latency of MPICH is
approximately 100 ![]() secs for SK-NET and 2330
secs for SK-NET and 2330 ![]() secs for ACEnic.
secs for ACEnic.
Again, we see that there are many severe dropouts for both LAM and MPICH using the ACEnic card.
Several things can be said regarding these performance results.
From the figures, it is evident that an MPI implementation layered on top of a TCP/IP protocol depends highly on the underlying TCP/IP performance.
Figure 5 shows MVICH performance. MVICH attains a maximum
throughput of 280 Mbps with latency of only 26 ![]() secs for message
sizes as low as 32KB. Again, we were unable to run message sizes
greater than 32KB. From the figure, it is evident that, as hoped,
MVICH performance
is much superior to that of LAM or MPICH using TCP/UDP as communication
transport.
secs for message
sizes as low as 32KB. Again, we were unable to run message sizes
greater than 32KB. From the figure, it is evident that, as hoped,
MVICH performance
is much superior to that of LAM or MPICH using TCP/UDP as communication
transport.