
Next: stack alignment and thread/processor
Up: 4. Memory bandwidth and
Previous: mutual exclusion.
Blocking is an optimization technique that allows a full cache use and thus
reduces memory bandwidth usage. Blocking is no always possible: for BLAS 1
and 2 the majority of data is accessed only one time making temporal locality
very low; on the other hand Level 3 operations use a three nested loop
structure with 2 dimension matrices making each matrix elements accessed more
than on time. We give an example for matrix matrix product C = A.B where
C, A and B are respectively m x n, m x p and p x n
matrices; in this case each element of A and B are accessed respectively
n and m times. The block method for matrix matrix product generally
consist of:
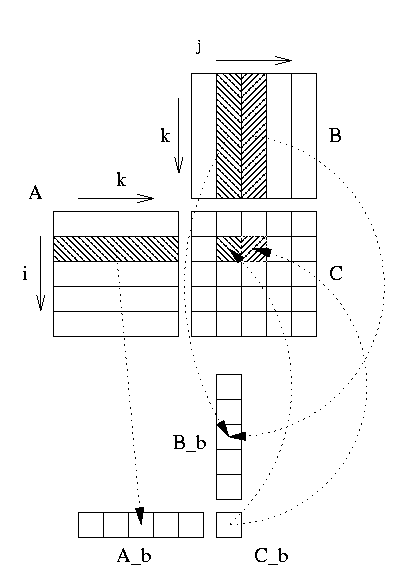
- split result matrix C into blocks Ci,j of size
nb x
nb, each blocks is constructed into a continuous array Cb which is
then copied back into the right Ci,j.
- matrices A and B are split into panels Ai and Bj of size nb x m and
k
x nb each panel is copied into continuous arrays Ab and Bb.
The choice of nb must ensure that Cb Ab and Bb fit into one
level of cache, usually L2 cache.
then:
![\begin{algorithmic}[1]
\FOR{$i=1$\ to $m/n_b$}
\STATE $A_b \leftarrow A_i$\FOR{$...
..._b}_k$,
\ENDFOR
\STATE $C_{i,j} \leftarrow C_b$\ENDFOR
\ENDFOR
\end{algorithmic}](img25.png)
We suppose for simplicity that nb divides m, n and
p. Figure ![[*]](cross_ref_motif.png) may help in understanding operations performed
on blocks. In the case of the previous algorithm matrix A is loaded only
one time into cache compared to the n times access of a classical ijk loop
while matrix B is still accessed m times. This simple block method greatly
reduce memory access and real codes may choose by looking at matrix size which
loop structure (ijk vs. jik) is best appropriate and if some matrix operand fits
totally into cache.
may help in understanding operations performed
on blocks. In the case of the previous algorithm matrix A is loaded only
one time into cache compared to the n times access of a classical ijk loop
while matrix B is still accessed m times. This simple block method greatly
reduce memory access and real codes may choose by looking at matrix size which
loop structure (ijk vs. jik) is best appropriate and if some matrix operand fits
totally into cache.
In the previous we where working on L2 cache and we does no talk about L1 cache
use. In fact L1 will be generally too small to handle a Ci,j block and
one panel of A and B but remember that operation performed at step 7 of the
previous algorithm is a matrix matrix product so each operand Abk and
Bbk is accessed
nb times: this part could also use a block method. Since nb is
relatively small the implementation may load only one of Cb, Abk,
Bbk into L1 cache and works with others from L2 cache.
The reader may refer to ATLAS source code and description
for a complete analysis and test of
block methods in various environments. Another projects for fast
matrix matrix multiply are
Phipac13[6] and the BLAIS[7]
library from MTL14.
Figure:
Block matrix matrix product.
|
|
Next: stack alignment and thread/processor
Up: 4. Memory bandwidth and
Previous: mutual exclusion.
Thomas Guignon
2000-08-24