void **env_base;
void (*env_blasth_signal_value)();
void blasth_daxpy(const int *n,
double *alpha,
double *X,
const int *incx,
double *Y,
const int *incy){
// realize Y = *alpha * X + Y
// where X and Y are vectors of
// size *n with respective increments
// of *incx and *incy
// executed by the
// master from the
// application program
env_base = (void **)&n;
env_blasth_signal_value = TH_DAXPY;
// tell the slave there is
// some job to do
blasth_master_sync();
// some job
// wait for the slave
blasth_master_sync_end();
}
void blasth(){
// excuted by the slave from the
// environement setup
while(1){
// wait for the master
blasth_sync();
//call the function set by the master
env_blasth_signal_value();
}
}
TH_DAXPY(){
// at this point env_base
// contains a pointer to the
// first needed parameter
// (int *)env_base[0] is a
// pointer to the size of vectors (*n)
// (double *)env_base[1] is a
// pointer to the scaling factor (*alpha)
// (double *)env_base[2] is a
// pointer to the first element
// of vector X
// ....
// some job
// tell the master
// that job is finished
blasth_sync_end();
}
The blasth_daxpy calling sequence is identical to the daxpy calling sequence
from a C program (the BLAS library is originally written in f77 so the
API is f77 compliant) and the parameters are written before the synchronization
variable so the strong memory ordering (for write operations) of the Pentium processor family ensure
that slave process will see exactly the same parameters in TH_DAXPY as the master in
blasth_daxpy.
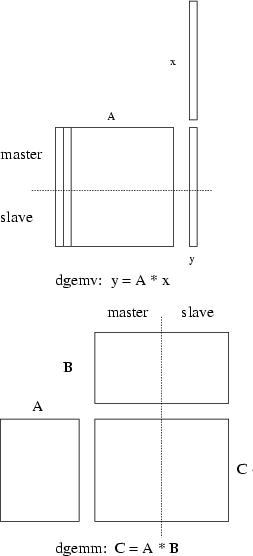
Data sharing is done by splitting the result between the master and the slave:
if the result is a vector the master has to construct the first half and slave has to
construct the second half; if the result is a matrix of size m x n the
master will construct either the first n/2 columns or m/2 rows and the slave
will construct the remaining columns or rows. We show splitting examples in
figure ![[*]](cross_ref_motif.png) for dgemv and dgemm (respectively matrix
vector product and matrix matrix product).
for dgemv and dgemm (respectively matrix
vector product and matrix matrix product).
We does not use cycling split of data to avoid cache line sharing between processors (especially when writing data). The splitting are also chosen to avoid temporary data which would require dynamic allocation.