A snapshot efficiently creates logical copies of disk partitions, which simplifies online backup application development. Rather than backing-up live data, backup application access snapshot logical copies while the server remains online and fully functional. Snapshot copies of live data are logically equivalent to copying a real partition, but use significantly less disk space. Before taking a snapshot, the file system or raw partition has to be frozen. This freezing ensures that the data on the disk is in a consistent state. Once the file system or raw partition is frozen, a snapshot can be taken. A snapshot manages any changes to data via the snapshot save area. Before a physical block is modified, a snapshot invokes a copy on write (COW) technique, copying the contents of blocks that are to be modified into the snapshot save area.
After the block is copied, its physical location can be overwritten by the changed data. After setting up a snapshot, only the first write of a given block causes a COW operation (``a COW push''). Subsequent writes are allowed to go directly to the real disk. Since block copy I/O activities occur in real time and only as blocks are changed, snapshot I/O has a significantly smaller performance impact than alternative online backup approaches.
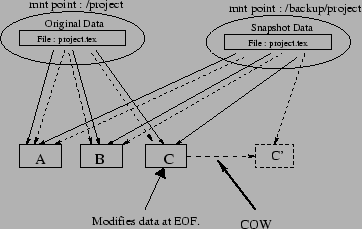
There are two different paths to access original data and snapshot
data. Consider Figure 1 where the file project.tex is made of
three blocks on disk: A, B and C. When a snapshot is taken, the
version of project.tex that exists in the snapshot is identical
to the one in the original file system. Assume that an application
modifies data at the end of the file, causing the contents of the
block C to change. The snapshot facility uses the COW policy that
copies the original block C to a location in snapshot save area,
creating a block ![]() . Dotted arrows in Figure 1 shows the
resulting situation.
. Dotted arrows in Figure 1 shows the
resulting situation.
Snapshots happen at the block level. Our design uses a layered device driver that enables snapshots to be persistent across panics and power failures. As this is at a device driver level, the snapshot facility will be available to all file systems and databases that work on block devices directly. Journalling as in ext3fs is an orthogonal issue as it is at the file system level.
Before starting the snapshot, data needs to be in frozen state. This paper doesn't address the way data is frozen. This is left to the applications like file system or database.
This paper is structured as follows. First, we discuss previous work. Next, we discuss the design and implementation of a layered device driver in Linux for persistent snapshots for a single node. We then discuss the design issues involved in developing a snapshot device driver in a clustered environment. We then present our implementation for a single node system along with details of the difficulties faced given the device driver environment in Linux 2.2. We then give some performance indicators and end with conclusions and future work. Note that we often use the term disk as a synonym for a partition but it should be clear what is being meant.