2 Signature domain
Figure 1: High-level architecture of signature computations
Signatures are a way to associate information with individual telephone
numbers. For each phone number, a typical signature contains information
about the characteristics of outgoing calls from that number and incoming
calls to it. The
outgoing data is often split into sub-categories based on the type of
call (for example, toll-free, international, intra-state, and other).
This section describes the process of computing signatures, discusses
the representation of signature data, and presents an example signature.
We first define some basic terminology.
Signatures maintain information about phone numbers rather
than customers. A second database can be used to match signature
data with customer information, but that process
is outside of Hancock's domain. A telephone number (973 555 1212)
contains an area code (973), an exchange (555), and a line number (1212). We often use the term exchange to mean the first
six digits of a phone number (973 555) and the term line to mean the
whole phone number. Hancock supports a few basic types for phone
numbers, dates, and times: area_code_t, exchange_t, line_t,
date_t, and time_t. It also supports a type for call records:
typedef struct {
line_t origin;
line_t dialed;
date_t connectTime;
time_t duration;
char isIncomplete;
char isIntl;
char isTollFree;
...
} callRec_t;
Each call record contains two phone numbers: the originating number
and the dialed number. Each record also stores the time the call was
connected (connectTime) and the duration of the call in seconds
(duration). Call records also contain boolean flags describing
the type of call: isIncomplete, isIntl, isTollFree,
etc.
2.1 Signature computation
We update signature data daily from the records of the calls made the
previous day.
Figure 1 shows a graphical
depiction of the typical architecture we use for such computations.
We first sort the call records by the originating phone number and
then update the outgoing portion of the signature for each phone number that
made a call.
We then repeat this process, sorting the call records by the dialed
number and updating the incoming portion of the signature for
each phone number that received a call.
This architecture reduces the I/O needed to
process a signature by ensuring good locality for references to the
stored signature data at the cost of a pair of external sorts.
2.2 Signature representation
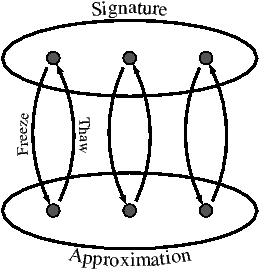
Figure 2: Signature data representation
As mentioned earlier, the size of signature files limits the
number of bytes we can keep for each phone number. As a result, we
cannot keep exact information for each line. Instead, we need to
approximate. Conceptually, in each signature we have two
views for our data: a precise form called the signature view and an approximate form called the approximation
view. We compute with the signature, but store the approximation.
The choice of these two views is application specific, as is
the method for converting between them.
We call the process of converting from the signature to the
approximation view freezing; the converse process, thawing.
(See Figure 2.) Note that thaw(freeze(v)) does not
necessarily equal v because freezing is often lossy.
Having two views for the data allows programmers to compute
with the natural representation while saving disk space, but it comes
at the cost of having to manage conversions between the two views.
2.3 Usage signature
This section describes the Usage signature, which we use as a
running example. Usage approximates cumulative daily call duration
for incoming calls, outgoing calls, and outgoing calls to toll-free
numbers. Usage uses the same structure to track all three types of
calls. In particular, the signature type for each is seconds; the
approximation type, a bucket number between zero and fifteen. The
buckets represent non-uniform ranges of durations. Bucket zero
corresponds to very short calls and serves as the default value for
lines with no recorded activity, while bucket fifteen corresponds to
long calls. Thawing converts bucket numbers to seconds by
associating a default duration with each bucket. Freezing identifies
the bucket with the appropriate range of times.
There are two parts to the daily Usage computation. First, we accumulate
the precise usage in seconds for a particular phone number for a
particular type of call, and then we blend that data with the
existing signature for that type of call. The code for blending
is:
blend(new, old) = new*lambda + old*(1-lambda)
Blending of this form is common in signature computations.
Pseudo-code for computing part of the Usage signature appears in
Figure 3. For brevity, we include only the code for
computing the outgoing portion of the signature for a single line,
called origin in the pseudo-code. A detailed version of
Usage that tracks some additional information can be found in Appendix
A.
outgoingUsage(origin, calls)
int cumTollFree = 0;
int cumOut = 0;
uApprox = Get usage data for origin
uSig = Convert uApprox from buckets to seconds
for c in calls do
if c.isTollFree then
cumTollFree += c.duration
else
cumOut += c.duration
endif
done
uSig.outTollFree =
blend(cumTollFree, uSig.outTollFree)
uSig.out = blend(cumOut, uSig.out)
uApprox = Convert uSig from seconds to buckets.
Record new uApprox data for origin
Figure 3: Pseudo-code for computing part of the Usage signature