


Next: Deployment Experience
Up: Performance Evaluation
Previous: Methodology
8.2 Results
We used PCs each having a 550 MHz AMD-K6 CPU, 64 MB of RAM
and RedHat Linux 6.2 as the SUT and for running Zebra.
We varied the number of nodes (
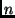 )
in the topology
in the range
)
in the topology
in the range
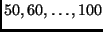 ;
and varied the number of LSAs per burst
(
;
and varied the number of LSAs per burst
(
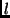 )
in the range
)
in the range
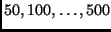 .
We set the inter-burst gap (
.
We set the inter-burst gap (
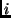 )
to one second,
and sent 100 bursts (
)
to one second,
and sent 100 bursts (
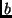 )
in each experiment.
For every value of
)
in each experiment.
For every value of
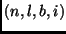 quadruplet, we carried out the experiment
three times.
quadruplet, we carried out the experiment
three times.

|
Figure 5:
LSAR performance (
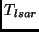 )
versus the number of LSAs
per burst for 50 and 100 nodes in the topology.
)
versus the number of LSAs
per burst for 50 and 100 nodes in the topology.
Figure 5 shows how
varies
as a function of the burst-size (
)
for two values of
.
Apart from running both LSAR and LSAG on the SUT, we also repeated the
same set of experiments with only LSAR running on the SUT.
As Figure 5 shows,
increases as the burst-size increases under all circumstances.
This can be explained as follows.
The inter-departure time while sending a burst of LSAs out at
Zebra is less than the inter-arrival time of receiving them back
since the inter-arrival time includes the
two-way propagation delay and the processing time per LSA.
As a result, the turn-around time (the
difference between receive-time and send-time)
is lowest for the first LSA within a burst,
and gradually increases for subsequent LSAs within the same burst.
Moreover, this disparity in the turn-around time
across LSAs widens as the burst-size increases, ultimately
resulting in a higher value of
for higher burst-sizes.
For the ``LSAR only'' case, the number of nodes in the
topology does not have much impact on
since the LSAR merely
deals with passing LSAs to LSAG (Zebra in this case) and archiving.
On the other hand,
is higher for the ``LSAR + LSAG'' case
than the ``LSAR only'' case
and is sensitive to the number of nodes in the topology.
Both these observations can be attributed to the LSAG
contending for CPU and memory with the LSAR on the SUT.
|
Figure 6:
LSAG performance (
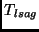 )
versus the number of nodes
in the network for the burst-size equal to 100 and 500 LSAs.
)
versus the number of nodes
in the network for the burst-size equal to 100 and 500 LSAs.
Figure 6 shows how
varies
as a function of the number of nodes (
)
for two values
of the burst-size.
As expected,
increases linearly with the number of nodes in
the topology. However, it is insensitive to the burst-size mainly
because of flow control imposed by TCP.
|
Figure 7:
Loss-rate at the LSAR (
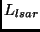 )
versus the number of LSAs
per burst for 50 and 100 nodes in the topology.
)
versus the number of LSAs
per burst for 50 and 100 nodes in the topology.
Figure 7 shows how
varies
as a function of the burst-size for two values of
.
As expected,
increases as the burst-size increases,
and
is higher for the ``LSAR + LSAG'' case than the ``LSAR
only'' case.
However,
is insensitive to the topology size.
For all the experiments, we checked that the LSAs not received by
Zebra did not exist in the LSAR archive implying that the LSAR never
received them due to a memory exhaustion in the IP stack on the SUT.
Unlike LSAR, the LSAG does not lose LSAs due to the use of TCP.
In fact, if given enough time at the end of the experiment,
the LSAG ultimately is able to process all the LSAs sent by the LSAR.
These results show that the LSAR and LSAG are capable of handling large
networks and high LSA-rate even on a low-end PC.
Furthermore, their performance degrades gracefully as
the load increases beyond their processing capability.
We believe that at high LSA-rates and excessive flapping as was the
case here the routers are more likely to melt-down before
the LSAR and LSAG processes especially if
a high-end server is used for running these processes.
This is because route processors used on even high-end routers do not
tend to be as powerful as the ones used on servers.
Furthermore, route processors typically run processes other than OSPF,
whereas the LSAR and LSAG can run on dedicated servers.
Next: Deployment Experience
Up: Performance Evaluation
Previous: Methodology
aman shaikh
2004-02-07

