All experiments were performed on a private ATM network between the SPARCstations. The machines were running in multiuser mode, but were not shared by other users.
Table 1: Throughput and Latency
The first experiment is a simple test to measure UDP latency and throughput, and TCP throughput. Its purpose is to demonstrate that the LRP architecture is competitive with traditional network subsystem implementations in term of these basic performance criteria. Moreover, we include the results for an unmodified SunOS kernel with the Fore ATM device driver for comparison. Latency was measured by ping-ponging a 1-byte message between two workstations 10,000 times, measuring the elapsed time and dividing to obtain round-trip latency. UDP throughput was measured using a simple sliding-window protocol (UDP checksumming was disabled.) TCP throughput was measured by transferring 24 Mbytes of data, with the socket send and receive buffers set to 32 KByte. Table 1 shows the results.
The numbers clearly demonstrate that LRP's basic performance is comparable with the unmodified BSD system from which it was derived. That is, LRP's improved overload behavior does not come at the cost of low-load performance. Furthermore, both BSD and LRP with our device driver perform significantly better than SunOS with the Fore ATM driver in terms of latency and UDP bandwidth. This is due to performance problems with the Fore driver, as discussed in detail in [1].
SunOS exhibits a performance anomaly that causes its base round-trip
latency--as measured on otherwise idle machines--to drop by almost
300 ![]() secs, when a compute-bound background process is running on
both the client and the server machine. We have observed this effect
in many different tests with SunOS 4.1.3_U1 on the SPARCstation
20. The results appear to be consistent with our theory that the cost
of dispatching a hardware/software interrupt and/or the receiver
process in SunOS depends on whether the machine is executing the idle
loop or a user process at the time a message arrives from the
network. Without access to source code, we were unable to pinpoint the
source of this anomaly.
secs, when a compute-bound background process is running on
both the client and the server machine. We have observed this effect
in many different tests with SunOS 4.1.3_U1 on the SPARCstation
20. The results appear to be consistent with our theory that the cost
of dispatching a hardware/software interrupt and/or the receiver
process in SunOS depends on whether the machine is executing the idle
loop or a user process at the time a message arrives from the
network. Without access to source code, we were unable to pinpoint the
source of this anomaly.
Since our modified systems (4.4BSD, NI-LRP, SOFT-LRP) are all based on SunOS, they were equally affected by this anomaly. Apart from affecting the base round-trip latency, the anomaly can perturb the results of tests with varying rates and concurrency of network traffic, since these factors influence the likelihood that an incoming packet interrupts a user process. To eliminate this variable, some of the experiments described below were run with low-priority, compute-bound processes running in the background, to ensure that incoming packets never interrupt the idle loop.
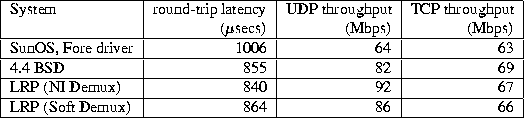
Figure 3: Throughput versus offered load
The next experiment was designed to test the behavior of the LRP architecture under overload. In this test, a client process sends short (14 byte) UDP packets to a server process on another machine at a fixed rate. The server process receives the packets and discards them immediately. Figure 3 plots the rate at which packets are received and consumed by the server process as a function of the rate at which the client transmits packets.
With the conventional 4.4 BSD network subsystem, the throughput increases with the offered load up to a maximum of 7400 pkts/sec. As the offered load increases further, the throughput of the system decreases, until the system approaches livelock at approximately 20,000 pkts/sec. With NI-LRP, on the other hand, throughput increases up to the maximum of 11,000 pkts/sec and remains at that rate as the offered load increases further. This confirms the effectiveness of NI-LRP's load shedding in the network interface, before any host resources have been invested in handling excess traffic. Instrumentation shows that the slight drop in NI-LRP's delivery rate beyond 19,000 pkts/sec is actually due to a reduction in the delivery rate of our ATM network, most likely caused by congestion-related phenomena in either the switch or the network interfaces.
SOFT-LRP refers to the case where demultiplexing is performed in the host's interrupt handler (soft demux). The throughput peaks at 9760 pkts/sec, but diminishes slightly with increasing rate due to the overhead of demultiplexing packets in the host's interrupt handler. This confirms that, while NI-LRP eliminates the possibility of livelock, SOFT-LRP merely postpones its arrival. However, on our experimental ATM network hardware/software platform, we have been unable to generate high enough packet rates to cause livelock in the SOFT-LRP kernel, even when using an in-kernel packet source on the sender.
For comparison, we have also measured the overload behavior of a kernel with early demultiplexing only (Early-Demux). The system performs demultiplexing in the interrupt handler (as in SOFT-LRP), drops packets whose destination socket's receiver queue is full, and otherwise schedules a software interrupt to process the packet. Due to the early demultiplexing, UDP's PCB lookup was bypassed, as in the LRP kernels. The system displays improved stability under overload compared with BSD, a result of early packet discard. The rate of decline under overload is comparable to that of SOFT-LRP, which is consistent with their use of the same demultiplexing mechanism. However, the throughput of the Early-Demux kernel is only between 40-65% of SOFT-LRP's throughput across the overload region.
Both variants of LRP display significantly better throughput than both the conventional 4.4 BSD system, and the Early-Demux kernel. The maximal delivered rate of NI-LRP is 51% and that of SOFT-LRP is 32% higher than BSD's maximal rate (11163 vs. 9760 vs. 7380 pkts/sec). Note that the throughput with SOFT-LRP at the maximal offered rate is within 12% of BSD's maximal throughput.
In order to understand the reasons for LRP's throughput gains, we instrumented the kernels to capture additional information. It was determined that the Maximum Loss Free Receive Rate (MLFRR) of SOFT-LRP exceeded that of 4.4BSD by 44% (9210 vs. 6380 pkts/sec). 4.4BSD and LRP drop packets at the socket queue or NI channel queue, respectively, at offered rates beyond their MLFRR. 4.4BSD additionally starts to drop packets at the IP queue at offered rates in excess of 15,000 pkts/sec. No packets were dropped due to lack of mbufs.
Obviously, early packet discard does not play a role in any performance differences at the MLFRR. With the exception of demultiplexing code (early demux in LRP versus PCB lookup in BSD) and differences in the device driver code, all four kernels execute the same 4.4BSD networking code. Moreover, the device driver and demultiplexing code used in Early-Demux and SOFT-LRP are identical, eliminating these factors as potential contributors to LRP's throughput gains. This suggests that the performance gains in LRP must be due in large part to factors such as reduced context switching, software interrupt dispatch, and improved memory access locality.
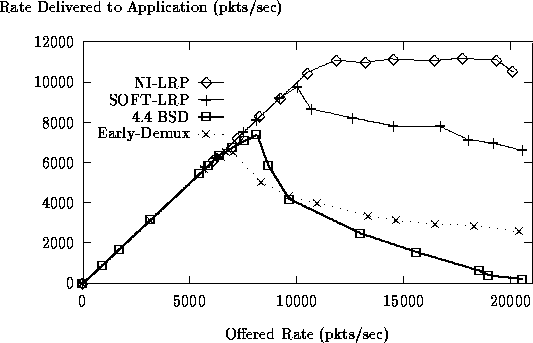
Figure 4: Latency with concurrent load
Our next experiment measures the latency that a client experiences when contacting a server process on a machine with high network load. The client, running on machine A, ping-pongs a short UDP message with a server process (ping-pong server) running on machine B. At the same time, machine C transmits UDP packets at a fixed rate to a separate server process (blast server) on machine B, which discards the packets upon arrival. Figure 4 plots the round-trip latency experienced by the client as a function of the rate at which packets are transmitted from machine C to the blast server (background load). To avoid the abovementioned performance anomaly in SunOS, the machines involved in the ping-pong exchange were each running a low-priority (nice +20) background process executing an infinite loop.
In all three systems, the measured latency varies with the background traffic rate. This variation is caused by the arrival of background traffic packets during the software processing of a ping-pong packet on the receiver. Arrivals of background traffic delay the processing of the request and/or the transmission of the response message, thus causing an increase in the round-trip delay. The magnitude of this delay is determined by two factors: The rate of arrivals, and the length of the interruptions caused by each arrival. This length of interruptions consists of the fixed interrupt processing time (hardware interrupt in LRP, hardware plus software interrupt in BSD), plus the optional time for scheduling of the blast server, and delivery of the message. This last component only occurs when the blast server's priority exceeds that of the ping-pong server, i.e., it is a function of SunOS's scheduling policy.
Instrumentation and modeling confirmed that the two main factors
shaping the graphs are (1) the length of the fixed interrupt
processing and (2) the scheduling-dependent overhead of delivering
messages to the blast receiver. The fixed interrupt overhead causes a
non-linear increase in the latency as the background traffic
rises. Due to the large overhead (hardware plus software interrupt,
including protocol processing, approximately 60 ![]() secs), the effect
is most pronounced in 4.4BSD. SOFT-LRP's reduced interrupt overhead
(hardware interrupt, including demux, approx. 25
secs), the effect
is most pronounced in 4.4BSD. SOFT-LRP's reduced interrupt overhead
(hardware interrupt, including demux, approx. 25 ![]() secs), results in
only a gradual increase. With NI-LRP (hardware interrupt with minimal
processing), this effect is barely noticeable.
secs), results in
only a gradual increase. With NI-LRP (hardware interrupt with minimal
processing), this effect is barely noticeable.
The second factor leads to an additional increase in latency at background traffic rates up to 7000 pkts/sec. The UNIX scheduler assigns priorities based on a process's recent CPU usage. As a result, it tends to favor a process that had been waiting for the arrival of a network packet, over the process that was interrupted by the packet's arrival. At low rates, the blast receiver is always blocked when a blast packet arrives. If the arrival interrupts the ping-pong server, the scheduler will almost always give the CPU to the blast receiver, causing a substantial delay of the ping-pong message. At rates around 6000 pkts/sec, the blast receiver is nearing saturation, thus turning compute-bound. As a result, its priority decreases, and the scheduler now preferentially returns the CPU to the interrupted ping-pong server immediately, eliminating this effect at high rates.
The additional delay caused by context switches to the blast server is
much stronger in BSD as in the two LRP systems (1020 vs. 750 ![]() secs
peak). This is a caused by the mis-accounting of network processing in
BSD. In that system, protocol processing of blast messages that arrive
during the processing of a ping-pong message is charged to the
ping-pong server process. This depletes the priority of the ping-pong
server, and increases the likelihood that the scheduler decides to
assign the CPU to the blast server upon arrival of a message. Note
that in a system that supports fixed-priority scheduling (e.g.,
Solaris), the influence of scheduling could be eliminated by assigning
the ping-pong server statically highest priority. The result is
nevertheless interesting in that it displays the effect of CPU
mis-accounting on latency in a system with a dynamic scheduling
policy.
secs
peak). This is a caused by the mis-accounting of network processing in
BSD. In that system, protocol processing of blast messages that arrive
during the processing of a ping-pong message is charged to the
ping-pong server process. This depletes the priority of the ping-pong
server, and increases the likelihood that the scheduler decides to
assign the CPU to the blast server upon arrival of a message. Note
that in a system that supports fixed-priority scheduling (e.g.,
Solaris), the influence of scheduling could be eliminated by assigning
the ping-pong server statically highest priority. The result is
nevertheless interesting in that it displays the effect of CPU
mis-accounting on latency in a system with a dynamic scheduling
policy.
With BSD, packet dropping at the IP queue makes latency measurements impossible at rates beyond 15,000 pkts/sec. In the LRP systems, no dropped latency packets were observed, which is due to LRP's traffic separation.
Our next experiment attempts to more closely model a mix of workloads
typical for network servers. Three processes run on a server
machine. The first server process, called the worker, performs a
memory-bound computation in response to an RPC call from a
client. This computation requires approximately 11.5 seconds of CPU
time and has a memory working set that covers a significant fraction
(35%) of the second level cache. The remaining two server processes
perform short computations in response to RPC requests. A client on
the other machine sends an RPC request to the worker process. While
the worker RPC is outstanding, the client sends RPC requests to the
remaining server processes in such a way that (1) each server has a
number of outstanding RPC requests at all times, and (2) the requests
are distributed near uniformly in time. (1) ensures that the RPC
server processes never block on receiving from the
network . The purpose of (2) is to make sure
there is no correlation between the scheduling of the server
processes, and the times at which requests are issued by the client.
Note that in this test, the clients generate requests at the maximal
throughput rate of the server. That is, the server is not operating
under conditions of overload. The RPC facility we used is based on
UDP datagrams.
. The purpose of (2) is to make sure
there is no correlation between the scheduling of the server
processes, and the times at which requests are issued by the client.
Note that in this test, the clients generate requests at the maximal
throughput rate of the server. That is, the server is not operating
under conditions of overload. The RPC facility we used is based on
UDP datagrams.
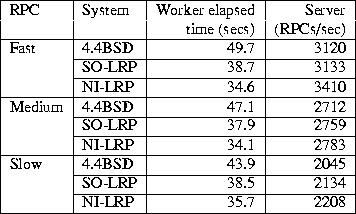
Table 2: Synthetic RPC Server Workload
Table 2 shows the results of this test. The total elapsed time for completion of the RPC to the worker process is shown in the third column. The rightmost column shows the rate at which the servers process RPCs, concurrently with each other and the worker process. ``Fast'', ``Medium'' and ``Slow'' correspond to tests with different amounts of per-request computations performed in the two RPC server processes. In each of the tests, the server's throughput (considering rate of RPCs completed and worker completion time) is lowest with BSD, higher with SOFT-LRP (SO-LRP), and highest with NI-LRP. In the ``Medium'' case, where the RPC rates are within 3% for each of the systems, the worker completion time with SOFT-LRP is 20% lower, and with NI-LRP 28% lower than with BSD. In the ``Fast'' case, NI-LRP achieves an almost 10% higher RPC rate and a 30% lower worker completion time than BSD. This confirms that LRP-based servers have increased throughput under high load. Note that packet discard is not a factor in this test, since the system is not operating under overload. Therefore, reduced context switching and improved locality must be responsible for the higher throughput with LRP.
Furthermore, the LRP systems maintain a fair allocation of CPU resources under high load. With SOFT-LRP and NI-LRP, the worker process's CPU share (CPU time / elapsed completion time) ranges from 29% to 33%, which is very close to the ideal 1/3 of the available CPU, compared to 23%-26% with BSD. This demonstrates the effect of mis-accounting in BSD, which tends to favor processes that perform intensive network communication over those that do not. Observe that this effect is distinct from, and independent of, the UNIX scheduler's tendency to favor I/O-bound processes.
Finally, we conducted a set of experiments with a real server application. We configured a machine running a SOFT-LRP kernel as a WWW server, using the NCSA httpd server software, revision 1.5.1. A set of informal experiments show that the server is dramatically more stable than a BSD based server under overload. To test this, Mosaic clients were contacting the server, while a test program running on a third machine was sending packets to a separate port on the server machine at a high rate (10,000 packets/sec). An HTTP server based on 4.4 BSD freezes completely under these conditions, i.e., it no longer responds to any HTTP requests, and the server console appears dead. With LRP and soft demux, the server responds to HTTP requests and the console is responsive, although some increase in response time is noticeable.
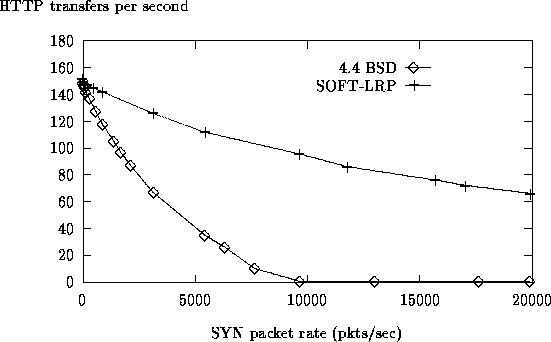
Figure 5: HTTP Server Throughput
The results of a quantitative experiment are shown in Figure 5. In this test, eight HTTP clients on a single machine continually request HTTP transfers from the server. The requested document is approximately 1300 bytes long. The eight clients saturate the HTTP server. A second client machine sends fake TCP connection establishment requests (SYN packets) to a dummy server running on the server machine that also runs the HTTP server. No connections are ever established as a result of these requests; TCP on the server side discards most of them once the dummy server's listen backlog is exceeded. To avoid known performance problems with BSD's PCB lookup function in HTTP servers [16], the TCP TIME_WAIT period was set to 500ms, instead of the default 30 seconds. The test were run for long periods of time to ensure steady-state behavior. Furthermore, the LRP system performed a redundant PCB lookup to eliminate any bias due to the greater efficiency of the early demultiplexing in LRP. Note that the results of this test were not affected by the TCP bug described in RFC 1948.
The graphs show the number of HTTP transfers completed by all clients, as a function of the rate of SYN packets to the dummy server, for 4.4 BSD and SOFT-LRP. The throughput of the 4.4 BSD-based HTTP server sharply drops as the rate of background requests increases, entering livelock at close to 10,000 SYN pkts/sec. The reason is that BSD's processing of SYN packets in software interrupt context starves the httpd server processes for CPU resources. Additionally, at rates above 6400 SYN pkts/sec, packets are dropped at BSD's shared IP queue. This leads to the loss of both TCP connection requests from real HTTP client and traffic on established TCP connections. Lost TCP connection requests cause TCP on the client side to back off exponentially. Lost traffic on established connections cause TCP to close its congestion window. However, the dominant factor in BSD's throughput decline appears to be the starvation of server processes.
With LRP, the throughput decreases relatively slowly. At a rate of
20,000 background requests per second, the LRP server still operates
at almost 50% of its maximal throughput. With LRP, traffic on each established TCP connection,
HTTP connection requests, and dummy requests are all demultiplexed
onto separate NI channels and do not interfere. As a result, traffic
to the dummy server does not cause the loss of HTTP traffic at
all. Furthermore, most dummy SYN packets are discarded early at the NI
channel queue. The predominant cause of the decline in the SOFT-LRP
based server's throughput is the overhead of software demultiplexing.
It should be noted that, independent of the use of LRP, an Internet server must limit the number of active connections to maintain stability. A related issue is how well LRP works with a large number of established connections, as has been observed on busy Internet servers [15]. SOFT-LRP uses one extra mbuf compared to 4.4BSD for each established TCP connection, so SOFT-LRP should scale well to large numbers of active connections. NI-LRP, on the other hand, dedicates resources on the network interface for each endpoint and is not likely to scale to thousands of allocated NI channels. However, most of the established connections on a busy web server are in the TIME_WAIT state. This can be exploited by deallocating an NI channel as soon as the associated TCP connection enters the TIME_WAIT state. Any subsequently arriving packets on this connection are queued at a special NI channel which is checked by TCP's slowtimo code. Since such traffic is rare, this does not affect NI-LRP's behavior in the normal case.