
The actual contention for the kernel data structures in our current implementation is low and we did not have the ability to create high contention at the time of writing.
To understand how our system behaves under heavy load, we have simulated insertion/deletion into a singly linked list under loads far heavier than would ever be encountered in the Cache Kernel.
Our simulation was run on the Proteus simulator [5], simulating 16 processors, a cache with 2 lines per set, a shared bus, and using the Goodman cache-coherence protocol. All times are reported in cycles from start of test until the last processor finishes executing. Memory latency is modeled at 10 times the cost of a cache reference. The cost of a DCAS is modeled at 17 extra cycles above the costs of the necessary memory references. The additional cost of a CAS over an unsynchronized instruction referencing shared memory is 9 cycles.
Four algorithms were simulated:
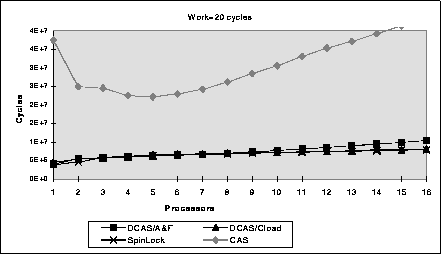
Figure 5: Performance of several synchronization algorithms with
local work = 20 and the number of processes per processor = 1
These simulations indicate that the Cache Kernel DCAS algorithms perform as well or better than CAS or spin locks.
Figure 5 shows the performance with 1 process per
processor, and minimal work between updates.
The basic cost of 10,000 updates is shown at N=1,
where all accesses are serialized and there
is no synchronization contention or bus contention.
At N=1, cache contention due to collisions is small, the hit rate in
the cache was over 99% in all algorithms.
At more than one processor, even assuming no
synchronization contention and no bus contention, completion time is
significantly larger because the objects must migrate from the cache
of one processor to another.
When processes/processor = 1 no processes are preempted.
In this case the difference
between
the non-concurrent algorithms is simply the bus contention and the
fixed overhead because we are not modelling page faults.
All degrade comparably, although DCAS/A&F suffers from bus-contention
on the count of active threads.
The Valois algorithm using CAS exploits concurrency
as the number of processors increase but the
overhead is large relative to the simpler algorithms.
The bus and memory contention are so much greater that the concurrency
does not gain enough to offset the loss due to overhead. Further,
synchronization contention causes the deletion of auxiliary nodes to
fail, so the number of nodes traversed increases with a larger number
of processes![]() .
Our DCAS algorithm performs substantially better than CAS,
even with concurrency.
.
Our DCAS algorithm performs substantially better than CAS,
even with concurrency.
Figure 6 displays the results from reducing the rate of access and interleaving list accesses in parallel with the local work.
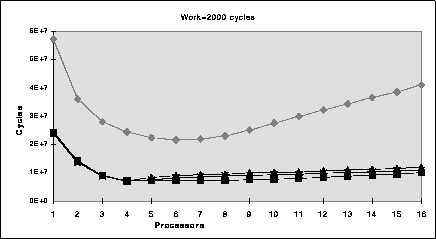
Figure 6: Performance of several synchronization algorithms with
local work = 2000 and the number of processes per processor = 1
Insertion/delete pairs appear to take 400 cycles with no cache interference so adding 2000 cycles of ``local work'' lets even the non-concurrent algorithms use about 4 or 5 processors concurrently to do useful work in parallel. Beyond that number of processors, the accesses to the list are serialized, and completion time is dominated by the time to do 10,000 insertion/deletion pairs. DCAS with either form of contention control performs comparably to spin-locks in the case of no delays and performance is significantly better than the CAS-only algorithm.
Figure 7 shows the results when 3 processes run on each processor. In this scenario, processes can be preempted --- possibly while holding a lock. As is expected, spin-locks are non-competitive once delays are introduced. In contrast, the non-blocking algorithms are only slightly affected by the preemption. The completion time of CAS is mostly unaffected, however the variance (not shown in the figures) increases due to reference counts held by preempted processes delaying the deletion of nodes --- when a process resumes after a delay, it can spend time releasing hundreds of nodes to the free list. These results also indicate how hardware advisory locking performs compared to operating system support in the style of Allemany and Felten. In the normal case, the lockholder experiences no delays and the waiters are notified immediately when the advisory lock is released. However, when a process is preempted, the waiters are not notified. When the waiter has backed off beyond a certain maximum threshold, it uses a normal Load rather than a Cload and no longer waits for the lock-holder. With a large number of processes, the occasional occurence of this (bounded) delay enables DCAS/A&F to outperform the cache-based advisory locking. However, the expected behavior of the Cache Kernel is for the waiters to be on the same processor as the lock-holder (either signal handlers or local context switch). In this case, the advisory lock does not prevent the waiter from making progress. Therefore, there is no advantage to the operating system notification and the lower overhead of advisory locking makes it preferable.
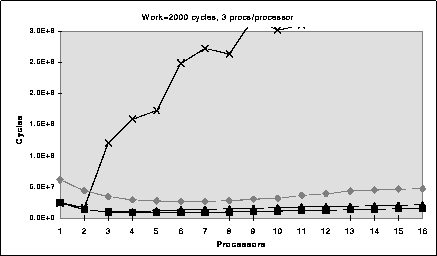
Figure 7: Performance of several synchronization algorithms with
local work = 2000 and the number of processes per processor = 3
Overall, DCAS performs comparably to, or better than, spin locks and CAS algorithms. Moreover, the code is considerably simpler than the CAS algorithm of Valois.
In these simulations, the number of processors accessing a single data structure is far higher than would occur under real loads and the rate of access to the shared data structure is far higher than one would expect on a real system. As previously noted, contention levels such as these are indicative of a poorly designed system and would have caused us to redesign this data structure. However, they do indicate that our techniques handle stress well.