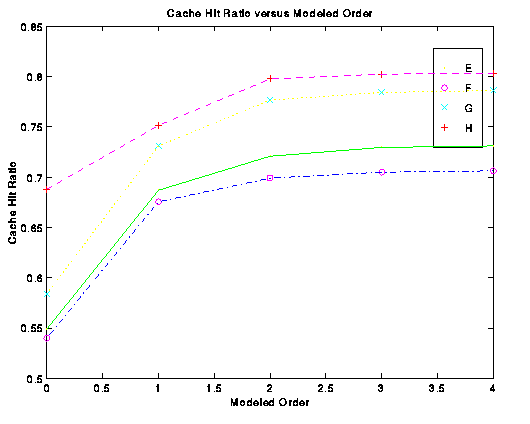
To see how much benefit was gained from each order of modeling we simulated models of order ranging from zero through four. Since we ignore the predictions of the zero order model, a zero order cache does not prefetch, and is therefore equivalent to an LRU cache. Figure 4 shows how performance varied over changes in model order. While we expected to gain mostly from the first and second orders, the second order improved performance more than we had expected, while fourth and higher orders appeared to offer negligible improvements. We hypothesize that the significant increase from the second order model comes from its ability to detect the combination of some frequently used file (e.g. make or xinit) and a task-specific file (e.g. Makefile or .xinitrc).

4 : Cache hit ratio versus model order (cache size 4 megabytes,
prefetch threshold 0.1).