The S-Client architecture introduced by Banga and Druschel [3] allows the generation of high HTTP request rates, using a small number of client machines. We used S-Clients to vary the load on the server. At the lowest load, the server is underutilized; at the higher loads, the server is the bottleneck.
For each request rate, we ran two kinds of benchmarks. In the naive benchmark, we used only enough S-Clients to generate the desired request rate. In the more realistic benchmark, we also used a load-adding client, to simulate the presence of long-delay connections. The load-adding client was run with 750 infinitely slow connections. (We show the effect of varying the number of slow connections in Section 5.2.)
All clients, in all of the experiments, repeatedly requested a single file of a fixed sized. In some experiments, we used an 8192-byte file; this is within the range of typical response sizes reported for the Web. In other experiments, we used a 1259-byte file; the shorter file size places more emphasis on per-connection overheads.
For our experiments using the Squid proxy server, we arranged things so that each request received by the proxy would generate an ``If-Modified-Since'' message from the proxy to the origin server, but the actual data would be served from the proxy's cache. The origin server ran on identical hardware (a 400Mhz AlphaStation 500), using the thttpd server program; we ensured that the origin server was never the bottleneck.
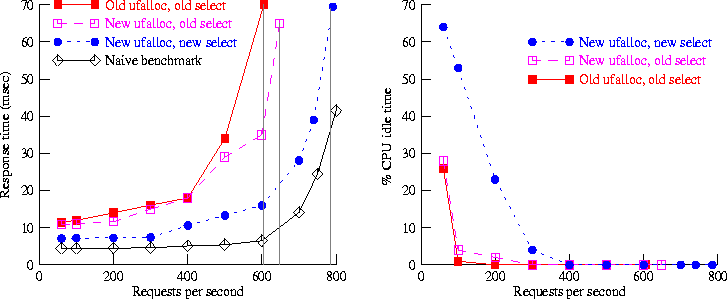
Figure 4: Squid idle time - 1259-byte files
Figure 3: Squid response times - 1259-byte files
Figure 3 shows how the response time of the Squid proxy varies with request rate, for 1259-byte files. The results for all kernels on the naive benchmark are effectively identical; for the realistic benchmark, we plot different curves for the different kernels. For each curve, the final point shows the ``saturation throughput'' for the given kernel; beyond this point, increasing the offered load did not increase throughput. This figure clearly shows that the presence of adding slow connections in the realistic benchmark drastically reduces the throughput achieved with the unmodified kernel relative to the naive benchmark. It also shows that our new implementations of select() and ufalloc() solve this performance problem. The performance of the fully modified kernel is nearly independent of the presence of many slow connections.
Figure 4 shows the effect of the new versions of select() and ufalloc() on server CPU idle time, also for 1259-byte files. At lower request rates, where the server is underutilized, our modifications greatly increase idle time for the realistic benchmark. The increase in idle time reflects the improved scalability of the system in the presence of cold connections.
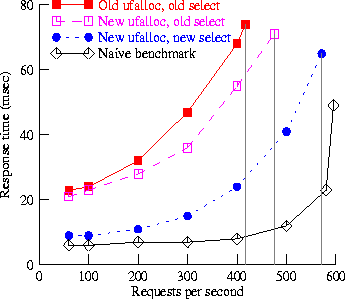
Figure 5: Squid response times - 8192-byte files
Figure 5 shows the response time of the Squid proxy for 8129-byte files. As in Figure 3, the fully modified kernel provides a higher saturation request rate than the original kernel, and yields lower response times at all request rates. However, the new kernel's performance on the realistic benchmark does not come quite as close to the performance of the naive benchmark; this may be due to data-cache collisions between the larger packets and the kernel's data structures. In these tests, the unmodified kernel showed no idle time for all request rates, while the new kernel showed some idle time up to 300 requests/sec.
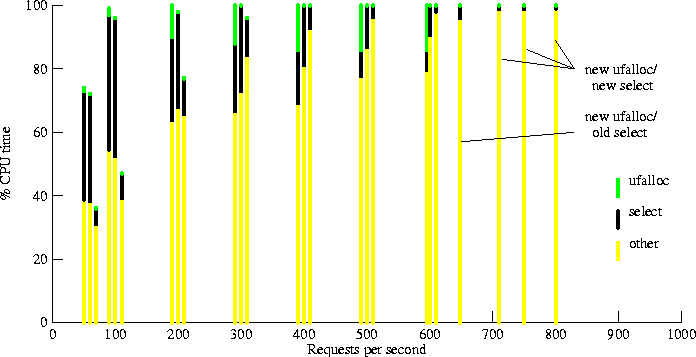
Figure 6: CPU share of ufalloc() and select(), Squid Proxy - 1259-byte files
We used DCPI to obtain CPU time profiles of the server. Figure 6 shows the fraction of CPU time used in select() and in ufalloc(), for various request rates, using 1259-byte files. (The results for tests using 8192-byte files are analogous.) In each group of three bars, the leftmost bar represents the unmodified kernel, the center bar represents the kernel with the new select(), and the rightmost bar represents the kernel with new versions of both select() and ufalloc(). At rates above 600 requests per second, each bar is independently labelled. The top section of each bar shows the CPU time spent in ufalloc(), and the middle section shows the CPU time spent in select(). The bottom section of each bar (``others'') shows the CPU time used for all other components of the server, including user-mode code. Idle time is not shown; it corresponds to the space above the bar, if any.
Figure 6 shows that the new ufalloc() almost entirely eliminates the CPU costs of descriptor allocation in all of the tested configurations. The new select() also costs much less than the old select().
When the server is underutilized, at rates below about 200 requests per second, the CPU profiles show that the new select() provides an additional performance impact: although we have not changed the implementation of any code covered by the ``others'' part of the profile, and the total throughput has not changed, the CPU costs of the ``others'' components has been reduced, relative to the unmodified kernel. We attribute this to better data-cache behavior, because the new select() has a much smaller data-cache footprint than the original implementation. The modified ufalloc() may also have a similar effect on cache performance. The improved data-cache footprint of select() is probably responsible for some of the throughput gains in the server-bound configurations.
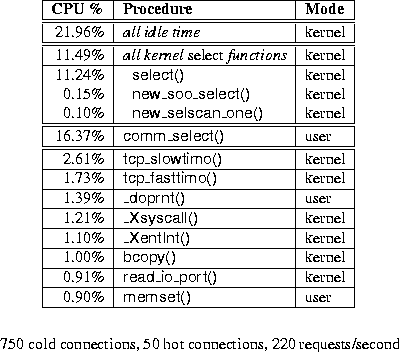
Table 2: Example profile for modified kernel
As can be seen in Figure 3, even with our kernel modifications, the realistic benchmark still causes a small performance degradation compared to the naive benchmark. We attribute this to the inherently poor scalability of the select() programming interface. This interface passes information proportional to the total number of active connections on each call to select(). Moreover, when select() returns, the user process must do work proportional to the total number of active connections to discover which descriptors have pending events. Finally, select() overwrites its input bitmaps, thus requiring additional user-mode work to create these bitmaps on each call. These costs cannot be eliminated with the current interface. In a separate publication [4], we propose a new, scalable interface to replace select()
Table 2 shows a profile of the modified kernel, made under the same conditions as the profile of the original kernel shown in Table 1. The new kernel spends 22% of the time in the idle loop, compared to almost no idle time for the original kernel. The original kernel spent about 22% of the CPU in select() and its subroutines, and 18% of the CPU in ufalloc(). The modified kernel spends 11% of the CPU in select(), and virtually none in ufalloc(). However, the busiest function in the system is now the user-level comm_select() function, using 16% of the CPU. The almost 28% of the CPU together consumed by the kernel select() and user-mode comm_select() functions is a result of the poorly scaling bitmap-based select() programming interface.
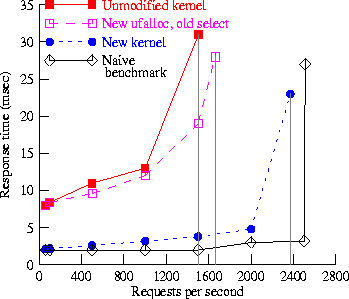
Figure 7: Response time for thttpd - 1259 byte files
Our experiments using the thttpd [24] Web server gave similar results. Using our modified kernel (with new implementations of both select() and ufalloc()), server throughput (at server saturation) improved by 58% for 1259-byte files, as shown in figure 7. For 8192-byte files, throughput increased by 37%; further improvement may have been limited by the available network bandwidth, rather than by the server. At lower request rates, the modified kernel showed much more idle time. For example, at 100 requests/sec. for a 1259-byte file, the unmodified kernel showed 16% idle time; the modified kernel showed 88% idle time. At at 100 requests/sec. for an 8192-byte file, the unmodified kernel had no idle time, but the modified kernel still showed 73% idle time.