
A revocation is required whenever a client should no longer have the access granted by a previously issued capability--due, for example, to a change in file permissions, or a file truncation or deletion. We seek a revocation scheme that is memory efficient, so that it can ideally be implemented in existing network-attached disks by simply changing their firmware (rather than, say, adding more hardware to them). The difficulty is that such disks have little memory and most of it is used to cache data (a typical cache size is 4 MB). It is thus important that the adopted scheme not take much memory: tens of kilobytes would be excellent, while megabytes would probably be too much.
Earlier schemes described in the literature, such as NASD [10] and SCARED [19], use object version numbers for revocations. In these systems, capabilities confer access only to a particular object version, so incrementing an object's version number suffices to revoke all old capabilities for it. Although this makes sense for variable-length objects, whose headers must be read first to find out where the desired data actually resides on disk, it is problematic for blocks: changing the permissions of a file would require updating a potentially large number of version numbers. For example, a 512 MB file could require updating 1 million version numbers, which would span 8 thousand blocks assuming 32 bits per version number.
Thus, we need a scheme that allows direct revocations of capabilities, without having to access the blocks to which the capability refers. A simple and economical method is to assign capability ID's to each capability so that the disk can keep track of valid capabilities through a bit vector. By doing so, it is possible to keep track of 524,288 capabilities with 64 KB, a modest amount of memory.
As a further optimization, we can assign the same ID to different capabilities, thereby reducing the number of possible revocations that need to be kept track of, but at the cost of not being able to independently revoke capabilities that share an ID. It makes sense to group together all the capabilities describing the same kind of access to different parts of one file, because they are almost always revoked together (the exception being partial truncation). One can further group together capabilities for the same file with different access modes; this makes file creation and deletion cheaper at the cost of making permission changes (e.g., chmod), which are rare, slightly more expensive.
This straightforward approach has a problem though: once an ID is revoked, its bit in the revocation vector must be kept set forever, lest some attacker hold the revoked capability and much later illegally use it again if the bit were cleared. Therefore, no matter how large the number of ID's, the system will sooner or later run out of them.
One way to solve this difficulty is to change ![]() (the secret key
shared by the disk and metadata server) whenever ID's run out, causing
all existing capabilities to become stale. The disk's bit vector can
now be cleared without fear of old invalidated capabilities springing
back to life and posing a security threat.
(the secret key
shared by the disk and metadata server) whenever ID's run out, causing
all existing capabilities to become stale. The disk's bit vector can
now be cleared without fear of old invalidated capabilities springing
back to life and posing a security threat.
This scheme has the unfortunately problem that when ![]() is changed
all capabilities become stale at once and will be rejected by the disk,
so all clients need to go back to the metadata server to get fresh
capabilities. Therefore, the metadata server may get overloaded with a
shower of requests in a short period. We call this the burstiness
problem.
is changed
all capabilities become stale at once and will be rejected by the disk,
so all clients need to go back to the metadata server to get fresh
capabilities. Therefore, the metadata server may get overloaded with a
shower of requests in a short period. We call this the burstiness
problem.
We solve the burstiness problem by using capability groups. The basic idea is to place capabilities into groups, and to invalidate groups when the system needs to recycle ID's. Intuitively, this avoids the burstiness problem because only a small fraction of capabilities is revoked when system runs out of ID's. More precisely, each capability has a capability ID and a group ID. The disk keeps a list of valid group ID's, and for each valid group, a bitmap with the revocation state of ID's. To know if a capability is still valid, the disk checks if its group ID is valid and, within that group, whether the capability ID is not revoked. To recycle the capability ID's in a group, the group ID is removed from the list of valid groups and it is replaced with a new group ID.4 Then, all capability ID's of the new group are marked valid.
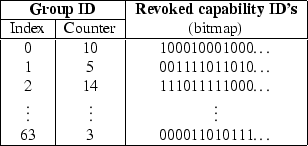
In our particular implementation, we divide a group ID into two
parts: a 6-bit index and a 64-bit counter. The index part is used to
index a 64-entry table, each entry of which contains a counter and 8,128
bits of revocation data (see Figure 3). The table
requires
![]() bits or 64 KB of RAM and supports up to
bits or 64 KB of RAM and supports up to
![]() simultaneous capabilities. A capability is
checked by looking up the entry corresponding to the index part of its
group ID, and verifying that the counter matches the one in the
capability's group ID. If so, the bit corresponding to the capability
ID is tested. Revocation of a capability is done similarly. Group
invalidation is done by clearing the group's bitmap and incrementing its
counter, effectively replacing its group ID with a fresh new one. All
these operations are very quick (small constant time) and space
efficiency is excellent: each capability takes on average less than 1.01
bits.
simultaneous capabilities. A capability is
checked by looking up the entry corresponding to the index part of its
group ID, and verifying that the counter matches the one in the
capability's group ID. If so, the bit corresponding to the capability
ID is tested. Revocation of a capability is done similarly. Group
invalidation is done by clearing the group's bitmap and incrementing its
counter, effectively replacing its group ID with a fresh new one. All
these operations are very quick (small constant time) and space
efficiency is excellent: each capability takes on average less than 1.01
bits.
 |
Note that capability groups alone do not reduce the total work on the metadata server over time, but the work gets spread over a longer period, avoiding the burstiness problem. We have done simulations with real trace data that confirm our predictions. Our simulations show that the peak load on the metadata server is reduced significantly with this technique (see Section 4.1 for more details).