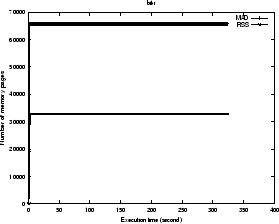
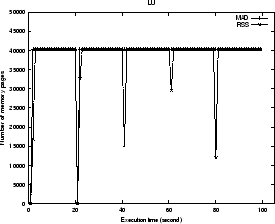
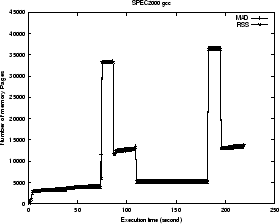
We have selected the following 3 both memory-intensive and CPU-intensive application programs:
The memory usage patterns of the three programs are plotted by
memory-time graphs for their isolated executions in Figure
5, 6, 7.
In the memory-time graph, the ![]() axis represents the execution time sequence,
and the
axis represents the execution time sequence,
and the ![]() axis represents two memory usage curves:
the memory allocation demand (MAD),
the resident set size (RSS), both can be obtained directly in the
kernel data structure of task_struct. In our current
implementation, the process we selected for protection
among the candidates is the one with least (MAD - RSS), which is
possibly easy to attain its full working set.
axis represents two memory usage curves:
the memory allocation demand (MAD),
the resident set size (RSS), both can be obtained directly in the
kernel data structure of task_struct. In our current
implementation, the process we selected for protection
among the candidates is the one with least (MAD - RSS), which is
possibly easy to attain its full working set.
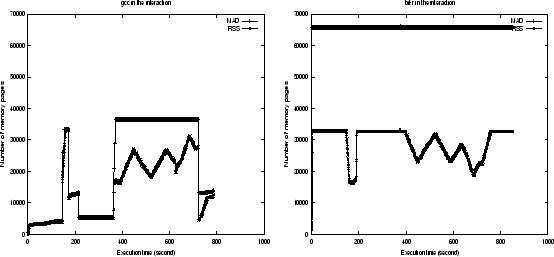
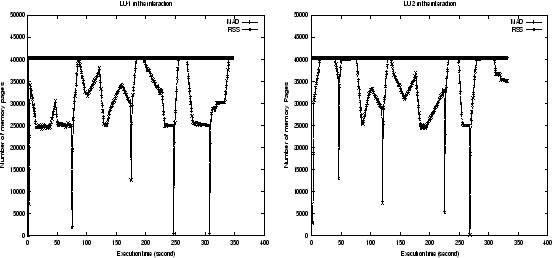
We first ran two groups of the interacting programs, gcc + bit-r with 31% memory shortage and LU-1 + LU-2 with 35% memory shortage, where LU-1, LU-2 are two executions of program LU, on the original Kernel 2.2.14. Then we ran the same groups on the kernel with our thrashing protection patch, where all the other experimental settings are the same. We present the memory usage measured by MAD and RSS of these experiments in Figures 8, 9, 10, and 11.
 |
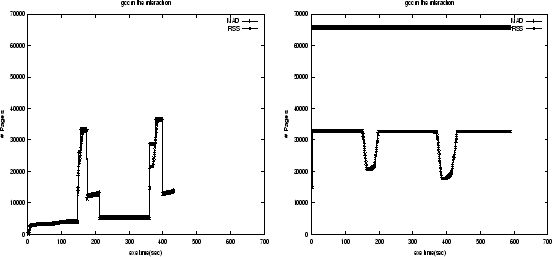 |
Figures 8 and 10 show that there were serious thrashing in Kernel 2.2, even though it takes considerable thrashing protection into account in its implementation.
The program gcc has two spikes in MAD and RSS due to its dynamic memory allocation demands and accesses (see Figure 7). In Figure 8, the first spike of gcc made the RSS curve of bit-r dropped sharply at the 165th second without causing thrashing. However, the second RSS spike of gcc, which just has only 7% more memory demand, incurred thrashing. Program gcc began to loose its pages at about 450th second before it could establish its working set, shown by the decreasing of its RSS curve. After that, both programs exhibited fluctuating RSS curves and started thrashing. During most of the thrashing period, both of them were in the waiting queue for the resolving of their page faults, leaving CPU idle. Comparatively, in the same kernel with thrashing protection, the second spike of gcc went smoothly without visible thrashing (see Figure 9). Once monitor facility detected the sign of thrashing, protection routine changed the behavior of replacement policy: gcc was selected to reduce its contribution of pages for replacement, thus quickly built its working set. After gcc finished its second spike, the released memory went to bit-r. Thus CPU was able to retain its utilization for almost the whole time. Our measurements show that with our patch the slowdown of gcc is reduced from 3.63 to 1.97, the slowdown of bit-r is reduced from 2.69 to 1.81. The number of page faults reductions for gcc and bit-r are 95.7% and 49.8% respectively.
 |
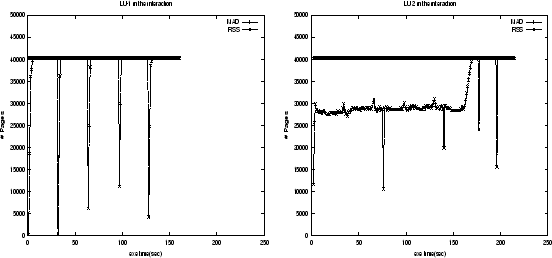 |
In Figure 10, both processes LU-1, LU-2 have the same memory usage pattern and started their executions at the same time. Thus frequent climbing slopes of RSS incurred memory frequent reallocations, and triggered fluctuating RSS curves, leading to inefficient memory usage and low CPU utilization. The dynamical memory demands from the processes caused the system to stay in the thrashing state for most of the time. However, when our protection patch is in effect, the protected process LU-1 can run very smoothly (see Figure 11), its RSS curve is much same as the one in the isolated execution (see Figure 6). This shows that our patch can responsively adapt replacement behavior to the dynamically changing demand of memory load from multiple processes, thus keep high CPU utilization. Our measurements show that the slowdown of LU-1 relative to its isolated execution time is reduced from 3.57 to 1.63, the slowdown of LU-2 is reduced from 3.40 to 2.18. The number of page faults reductions for LU-1 and LU-2 are 99.4% and -39.6% respectively. Though the number of page faults of LU-2 is increased, its execution time is still greatly reduced, which is partly because of the increased I/O bandwidth when its peer process LU-1 has greatly reduced its page faults due to the protection.