


To specify QoS properties in QML, we need a way to formally quantify the various aspects of QoS. A QoS category denotes a specific non-functional characteristic of systems that we are interested in specifying. Reliability , security , and performance are examples of such categories. Each category consists of one or more dimensions that represent a metric for one aspect of the category. Throughput would be a dimension of the performance QoS category. We represent QoS categories and dimensions as user-defined types in QML.
To meaningfully characterize services with QoS categories we need valid dimensions. We are particularly interested in the dimensions that characterize services without exposing internal design and implementation details. Such dimensions enable the specification of QoS properties that are relevant and understandable for, in principle, any service regardless of implementation technology.
We describe a set of dimensions for reliability and performance. In [] we have reviewed a variety of literature and systems on reliability including work by Gray et al. [], Cristian [], Reibman [], Birman, [], Maffeis [], Littlewood [], and others. As a result we propose the following dimensions for characterizing the reliability of distributed object services:

We use the measurable quantities of time to failure ( TTF ) and time to repair ( TTR ). Availability is the probability that a service is available when a client attempts to use it. Assume for example that service is down totally one week a year, then the availability would be 51/52, which is approximately 0.98. Continuous availability assesses the probability with which a client can access a service an infinite number of times during a particular time period. The service is expected not to fail and to retain all state information during this time period. We could for example require that a particular client can use a service for a 60 minute period without failure with a probability of 0.999. Continuous availability is different from availability in that it requires subsequent use of a service to succeed but only for a limited time period.
The failure masking dimension is used to describe what kind of failures a server may expose to its clients. A client must be able to detect and handle any kind of exposed failure. The above table lists the set of all possible failures that can be exposed by services in general. The QoS specification for a particular service will list the subset of failures exposed by that service.
We base our categorization of failure types---shown in Figure 4 ---on the work by Cristian []. If a service exposes omission failures, clients must be prepared to handle a situation where the service simply omits to respond to requests. If a service exposes response failures, it might respond with a faulty return value or an incorrect state transition. Finally, if the service exposes timing failures, it may respond in an untimely manner. Timing failures have two subtypes: late and early timing errors. Services can have any combination of failure masking characteristics.
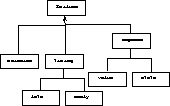
Figure: Failure type hierarchy
Operation semantics describe how requests are handled in the case of a failure. We can specify that issued requests are executed exactlyOnce , atLeastOnce , or atMostOnce .
Server failure describes the way in which a service can fail. That is, whether it will halt indefinitely, restart in a well defined initialState , or restart rolledBack to a previous check point.
The number of failures gives a likely upper bound for the number of times the service will fail during a specific time period.
When a service fails the client needs to know whether it can use the existing reference or whether it needs to rebind to the service after the service has recovered. The rebinding policy is used to specify this aspect of reliability.
Finally, we propose that the client also needs to know if data returned by the service still is valid after the service has failed and been restarted. To specify this we need to associate data policy with entities such as return values and out arguments.
For the purpose of this paper we will propose a minimal set of dimensions for characterizing performance. We are only including throughput and latency . Throughput is the transfer rate for information, and can, for example, be specified as megabytes per second. Latency measures the time between the point that an invocation was issued and the time at which the response was received by the client.
Dimensions such as those presented here constitute the vocabulary for QoS specification languages. We use the dimensions to describe the example in section 6.