



Next: Profile Engines
Up: Architecture of the WWW
Previous: HTTP Request/Response Filters
A usage profile is a representation of a user's or group's usage
pattern of the Web. The profile is learned over time by monitoring
the stream of HTTP requests of users. Using the profile to determine which
documents to pre-fetch, rather than simply using the document layout,
can significantly improve the efficiency of pre-fetching. The usage
profile is a directed weighted graph, where the nodes represent URLs
and edges represent the access path. The weight of a node u
indicates the frequency of access of the corresponding URL, while the
weight of an edge (u,v) indicates the frequency of access of the
URL v immediately following the URL u. In order to reflect
the changing access patterns of users and the temporal locality of
accesses, recent history is given precedence in the weighting heuristic.
Let nt(u) represent the number of accesses of node u (i.e. the URL
corresponding to node u) during the time interval t, nt(u, v)
represent the number of accesses of node v immediately following
node u, wt(u) represent the weight of node u after the time
interval t, and wt(u, v) represent the weight of edge (u, v)
after the time interval t. The weights of nodes and edges are computed
as follows:
where 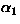 ,
, 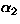 ,
, 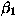 , and
, and 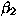 are constants which
indicate the relative weights of recent history versus past history.
These constants, along with the time window t, play a key role in
determining how effectively the profile adapts to the changing user access
patterns. Modifying these parameters will determine whether the profile
does long term adaptation or short term adaptation.
Based on our own experience, we have currently set
are constants which
indicate the relative weights of recent history versus past history.
These constants, along with the time window t, play a key role in
determining how effectively the profile adapts to the changing user access
patterns. Modifying these parameters will determine whether the profile
does long term adaptation or short term adaptation.
Based on our own experience, we have currently set 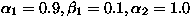 , and
, and 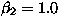 . This means that we have
set a very high weightage to previous history. This is because we wanted
our system to be insensitive to spurous bursts of visits to sites that
will not be visited again i.e. long term adaptation. We have set t to
be the time between two successive sessions. This means that the
weights are recalculated at the beginning of every Web session.
While the current values of the constants are based on what worked for our
usage profiles, we plan to do more experiments in order to determine the
weights in the graph. While our weights are determined solely by frequency
of access, we plan to use the following parameters for determining weights
in the future: percentage of membership that uses an edge or node for group
profiles, expected latency, liveliness of documents, and size.
. This means that we have
set a very high weightage to previous history. This is because we wanted
our system to be insensitive to spurous bursts of visits to sites that
will not be visited again i.e. long term adaptation. We have set t to
be the time between two successive sessions. This means that the
weights are recalculated at the beginning of every Web session.
While the current values of the constants are based on what worked for our
usage profiles, we plan to do more experiments in order to determine the
weights in the graph. While our weights are determined solely by frequency
of access, we plan to use the following parameters for determining weights
in the future: percentage of membership that uses an edge or node for group
profiles, expected latency, liveliness of documents, and size.
Group usage profiles are a natural extension of the idea of exploiting
individual usage profiles to predictively pre-fetch documents. They also
fit naturally into
collaborative filtering of documents discussed in [10]. Group usage
profiles are inherited by users that join the group. Thus, a new user would first enroll in
several groups. This will ensure that there is some form of informed
speculative pre-fetch service for the user while his/her own usage pattern is being
learned by the local profile engine. In addition, as the interests of the group
change over time, the user will be able to inherit the changes automatically.
In the case of group profiles, we keep more state. In particular, we are
interested in the number of members in a particular group who have visited
a particular URL and who have used a particular edge. This allows us to
make recommendations on which URLs to pre-fetch. For example, if more than
50% of the group uses a particular edge (u,v), then we recommend v when
a member of the group visits u.
While individual profiles are used for predictive pre-fetches, group profiles
serve two purposes. First, a group profile is inherited by a new member to a
group, hence, while his/her individual profile is being learnt, it is still
possible to predictively pre-fetch. Second, group profiles are useful for
notifying a member of pages that most of the other members of the group are
visiting.
Next: Profile Engines
Up: Architecture of the WWW
Previous: HTTP Request/Response Filters
Sau Loon Tong
10/26/1997